Базовые алгоритмы нахождения кратчайших путей во взвешенных графах
Время на прочтение
5 мин
Количество просмотров 240K
Наверняка многим из гейм-девелоперов (или просто людям, увлекающимися програмировагнием) будет интересно услышать эти четыре важнейших алгоритма, решающих задачи о кратчайших путях.
Сформулируем определения и задачу.
Графом будем называть несколько точек (вершин), некоторые пары которых соединены отрезками (рёбрами). Граф связный, если от каждой вершины можно дойти до любой другой по этим отрезкам. Циклом назовём какой-то путь по рёбрам графа, начинающегося и заканчивающегося в одной и той же вершине. И ещё граф называется взвешенным, если каждому ребру соответствует какое-то число (вес). Не может быть двух рёбер, соединяющих одни и те же вершины.
Каждый из алгоритмов будет решать какую-то задачу о кратчайших путях на взвешенном связном. Кратчайший путь из одной вершины в другую — это такой путь по рёбрам, что сумма весов рёбер, по которым мы прошли будет минимальна.
Для ясности приведу пример такой задачи в реальной жизни. Пусть, в стране есть несколько городов и дорог, соединяющих эти города. При этом у каждой дороги есть длина. Вы хотите попасть из одного города в другой, проехав как можно меньший путь.
Считаем, что в графе n вершин и m рёбер.
Пойдём от простого к сложному.
Алгоритм Флойда-Уоршелла
Находит расстояние от каждой вершины до каждой за количество операций порядка n^3. Веса могут быть отрицательными, но у нас не может быть циклов с отрицательной суммой весов рёбер (иначе мы можем ходить по нему сколько душе угодно и каждый раз уменьшать сумму, так не интересно).
В массиве d[0… n — 1][0… n — 1] на i-ой итерации будем хранить ответ на исходную задачу с ограничением на то, что в качестве «пересадочных» в пути мы будем использовать вершины с номером строго меньше i — 1 (вершины нумеруем с нуля). Пусть идёт i-ая итерация, и мы хотим обновить массив до i + 1-ой. Для этого для каждой пары вершин просто попытаемся взять в качестве пересадочной i — 1-ую вершину, и если это улучшает ответ, то так и оставим. Всего сделаем n + 1 итерацию, после её завершения в качестве «пересадочных» мы сможем использовать любую, и массив d будет являться ответом.
n итераций по n итераций по n итераций, итого порядка n^3 операций.
Псевдокод:
прочитать g // g[0 ... n - 1][0 ... n - 1] - массив, в котором хранятся веса рёбер, g[i][j] = 2000000000, если ребра между i и j нет
d = g
for i = 1 ... n + 1
for j = 0 ... n - 1
for k = 0 ... n - 1
if d[j][k] > d[j][i - 1] + d[i - 1][k]
d[j][k] = d[j][i - 1] + d[i - 1][k]
вывести d
Алгоритм Форда-Беллмана
Находит расстояние от одной вершины (дадим ей номер 0) до всех остальных за количество операций порядка n * m. Аналогично предыдущему алгоритму, веса могут быть отрицательными, но у нас не может быть циклов с отрицательной суммой весов рёбер.
Заведём массив d[0… n — 1], в котором на i-ой итерации будем хранить ответ на исходную задачу с ограничением на то, что в путь должно входить строго меньше i рёбер. Если таких путей до вершины j нет, то d[j] = 2000000000 (это должна быть какая-то недостижимая константа, «бесконечность»). В самом начале d заполнен 2000000000. Чтобы обновлять на i-ой итерации массив, надо просто пройти по каждому ребру и попробовать улучшить расстояние до вершин, которые оно соединяет. Кратчайшие пути не содержат циклов, так как все циклы неотрицательны, и мы можем убрать цикл из путя, при этом длина пути не ухудшится (хочется также отметить, что именно так можно найти отрицательные циклы в графе: надо сделать ещё одну итерацию и посмотреть, не улучшилось ли расстояние до какой-нибудь вершины). Поэтому длина кратчайшего пути не больше n — 1, значит, после n-ой итерации d будет ответом на задачу.
n итераций по m итераций, итого порядка n * m операций.
Псевдокод:
прочитать e // e[0 ... m - 1] - массив, в котором хранятся рёбра и их веса (first, second - вершины, соединяемые ребром, value - вес ребра)
for i = 0 ... n - 1
d[i] = 2000000000
d[0] = 0
for i = 1 ... n
for j = 0 ... m - 1
if d[e[j].second] > d[e[j].first] + e[j].value
d[e[j].second] = d[e[j].first] + e[j].value
if d[e[j].first] > d[e[j].second] + e[j].value
d[e[j].first] = d[e[j].second] + e[j].value
вывести d
Алгоритм Дейкстры
Находит расстояние от одной вершины (дадим ей номер 0) до всех остальных за количество операций порядка n^2. Все веса неотрицательны.
На каждой итерации какие-то вершины будут помечены, а какие-то нет. Заведём два массива: mark[0… n — 1] — True, если вершина помечена, False иначе, d[0… n — 1] — для каждой вершины будет храниться длина кратчайшего пути, проходящего только по помеченным вершинам в качестве «пересадочных». Также поддерживается инвариант того, что для помеченных вершин длина, указанная в d, и есть ответ. Сначала помечена только вершина 0, а g[i] равно x, если 0 и i соединяет ребро весом x, равно 2000000000, если их не соединяет ребро, и равно 0, если i = 0.
На каждой итерации мы находим вершину, с наименьшим значением в d среди непомеченных, пусть это вершина v. Тогда значение d[v] является ответом для v. Докажем. Пусть, кратчайший путь до v из 0 проходит не только по помеченным вершинам в качестве «пересадочных», и при этом он короче d[v]. Возьмём первую встретившуюся непомеченную вершину на этом пути, назовём её u. Длина пройденной части пути (от 0 до u) — d[u]. len >= d[u], где len — длина кратчайшего пути из 0 до v (т. к. отрицательных рёбер нет), но по нашему предположению len меньше d[v]. Значит, d[v] > len >= d[u]. Но тогда v не подходит под своё описание — у неё не наименьшее значение d[v] среди непомеченных. Противоречие.
Теперь смело помечаем вершину v и пересчитываем d. Так делаем, пока все вершины не станут помеченными, и d не станет ответом на задачу.
n итераций по n итераций (на поиск вершины v), итого порядка n^2 операций.
Псевдокод:
прочитать g // g[0 ... n - 1][0 ... n - 1] - массив, в котором хранятся веса рёбер, g[i][j] = 2000000000, если ребра между i и j нет
d = g
d[0] = 0
mark[0] = True
for i = 1 ... n - 1
mark[i] = False
for i = 1 ... n - 1
v = -1
for i = 0 ... n - 1
if (not mark[i]) and ((v == -1) or (d[v] > d[i]))
v = i
mark[v] = True
for i = 0 ... n - 1
if d[i] > d[v] + g[v][i]
d[i] = d[v] + g[v][i]
вывести d
Алгоритм Дейкстры для разреженных графов
Делает то же самое, что и алгоритм Дейкстры, но за количество операций порядка m * log(n). Следует заметить, что m может быть порядка n^2, то есть эта вариация алгоритма Дейкстры не всегда быстрее классической, а только при маленьких m.
Что нам нужно в алгоритме Дейкстры? Нам нужно уметь находить по значению d минимальную вершину и уметь обновлять значение d в какой-то вершине. В классической реализации мы пользуемся простым массивом, находить минимальную по d вершину мы можем за порядка n операций, а обновлять — за 1 операцию. Воспользуемся двоичной кучей (во многих объектно-ориентированных языках она встроена). Куча поддерживает операции: добавить в кучу элемент (за порядка log(n) операций), найти минимальный элемент (за 1 операцию), удалить минимальный элемент (за порядка log(n) операций), где n — количество элементов в куче.
Создадим массив d[0… n — 1] (его значение то же самое, что и раньше) и кучу q. В куче будем хранить пары из номера вершины v и d[v] (сравниваться пары должны по d[v]). Также в куче могут быть фиктивные элементы. Так происходит, потому что значение d[v] обновляется, но мы не можем изменить его в куче. Поэтому в куче могут быть несколько элементов с одинаковым номером вершины, но с разным значением d (но всего вершин в куче будет не более m, я гарантирую это). Когда мы берём минимальное значение в куче, надо проверить, является ли этот элемент фиктивным. Для этого достаточно сравнить значение d в куче и реальное его значение. А ещё для записи графа вместо двоичного массива используем массив списков.
m раз добавляем элемент в кучу, получаем порядка m * log(n) операций.
Псевдокод:
прочитать g // g[0 ... n - 1] - массив списков, в i-ом списке хранятся пары: first - вершина, соединённая с i-ой вершиной ребром, second - вес этого ребра
d[0] = 0
for i = 0 ... n - 1
d[i] = 2000000000
for i in g[0] // python style
d[i.first] = i.second
q.add(pair(i.second, i.first))
for i = 1 ... n - 1
v = -1
while (v = -1) or (d[v] != val)
v = q.top.second
val = q.top.first
q.removeTop
mark[v] = true
for i in g[v]
if d[i.first] > d[v] + i.second
d[i.first] = d[v] + i.second
q.add(pair(d[i.first], i.first))
вывести d
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Given a graph where every edge has weight as either 0 or 1. A source vertex is also given in the graph. Find the shortest path from the source vertex to every other vertex.
For Example:
Input : Source Vertex = 0 and below graph
Output : Shortest distances from given source
0 0 1 1 2 1 2 1 2
Explanation :
Shortest distance from 0 to 0 is 0
Shortest distance from 0 to 1 is 0
Shortest distance from 0 to 2 is 1
..................
In normal BFS of a graph, all edges have equal weight but in 0-1 BFS some edges may have 0 weight and some may have 1 weight. In this, we will not use a bool array to mark visited nodes but at each step, we will check for the optimal distance condition. We use a double-ended queue to store the node. While performing BFS if an edge having weight = 0 is found node is pushed at front of the double-ended queue and if an edge having weight = 1 is found, it is pushed to the back of the double-ended queue.
The approach is similar to Dijkstra that if the shortest distance to the node is relaxed by the previous node then only it will be pushed into the queue.
The above idea works in all cases, when pop a vertex (like Dijkstra), it is the minimum weight vertex among the remaining vertices. If there is a 0-weight vertex adjacent to it, then this adjacent has the same distance. If there is a 1 weight adjacent, then this adjacent has maximum distance among all vertices in the dequeue (because all other vertices are either adjacent to the currently popped vertex or adjacent to previously popped vertices).
Below is the implementation of the above idea.
C++
#include<bits/stdc++.h>
using namespace std;
#define V 9
struct node
{
int to, weight;
};
vector <node> edges[V];
void zeroOneBFS(int src)
{
int dist[V];
for (int i=0; i<V; i++)
dist[i] = INT_MAX;
deque <int> Q;
dist[src] = 0;
Q.push_back(src);
while (!Q.empty())
{
int v = Q.front();
Q.pop_front();
for (int i=0; i<edges[v].size(); i++)
{
if (dist[edges[v][i].to] > dist[v] + edges[v][i].weight)
{
dist[edges[v][i].to] = dist[v] + edges[v][i].weight;
if (edges[v][i].weight == 0)
Q.push_front(edges[v][i].to);
else
Q.push_back(edges[v][i].to);
}
}
}
for (int i=0; i<V; i++)
cout << dist[i] << " ";
}
void addEdge(int u, int v, int wt)
{
edges[u].push_back({v, wt});
edges[v].push_back({u, wt});
}
int main()
{
addEdge(0, 1, 0);
addEdge(0, 7, 1);
addEdge(1, 7, 1);
addEdge(1, 2, 1);
addEdge(2, 3, 0);
addEdge(2, 5, 0);
addEdge(2, 8, 1);
addEdge(3, 4, 1);
addEdge(3, 5, 1);
addEdge(4, 5, 1);
addEdge(5, 6, 1);
addEdge(6, 7, 1);
addEdge(7, 8, 1);
int src = 0;
zeroOneBFS(src);
return 0;
}
Java
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
public class ZeroOneBFS {
private static class Node {
int to;
int weight;
public Node(int to, int wt) {
this.to = to;
this.weight = wt;
}
}
private static final int numVertex = 9;
private ArrayList<Node>[] edges = new ArrayList[numVertex];
public ZeroOneBFS() {
for (int i = 0; i < edges.length; i++) {
edges[i] = new ArrayList<Node>();
}
}
public void addEdge(int u, int v, int wt) {
edges[u].add(edges[u].size(), new Node(v, wt));
edges[v].add(edges[v].size(), new Node(u, wt));
}
public void zeroOneBFS(int src) {
int[] dist = new int[numVertex];
for (int i = 0; i < numVertex; i++) {
dist[i] = Integer.MAX_VALUE;
}
Deque<Integer> queue = new ArrayDeque<Integer>();
dist[src] = 0;
queue.addLast(src);
while (!queue.isEmpty()) {
int v = queue.removeFirst();
for (int i = 0; i < edges[v].size(); i++) {
if (dist[edges[v].get(i).to] >
dist[v] + edges[v].get(i).weight) {
dist[edges[v].get(i).to] =
dist[v] + edges[v].get(i).weight;
if (edges[v].get(i).weight == 0) {
queue.addFirst(edges[v].get(i).to);
} else {
queue.addLast(edges[v].get(i).to);
}
}
}
}
for (int i = 0; i < dist.length; i++) {
System.out.print(dist[i] + " ");
}
}
public static void main(String[] args) {
ZeroOneBFS graph = new ZeroOneBFS();
graph.addEdge(0, 1, 0);
graph.addEdge(0, 7, 1);
graph.addEdge(1, 7, 1);
graph.addEdge(1, 2, 1);
graph.addEdge(2, 3, 0);
graph.addEdge(2, 5, 0);
graph.addEdge(2, 8, 1);
graph.addEdge(3, 4, 1);
graph.addEdge(3, 5, 1);
graph.addEdge(4, 5, 1);
graph.addEdge(5, 6, 1);
graph.addEdge(6, 7, 1);
graph.addEdge(7, 8, 1);
int src = 0;
graph.zeroOneBFS(src);
return;
}
}
Python3
from sys import maxsize as INT_MAX
from collections import deque
V = 9
class node:
def __init__(self, to, weight):
self.to = to
self.weight = weight
edges = [0] * V
for i in range(V):
edges[i] = []
def zeroOneBFS(src: int):
dist = [0] * V
for i in range(V):
dist[i] = INT_MAX
Q = deque()
dist[src] = 0
Q.append(src)
while Q:
v = Q[0]
Q.popleft()
for i in range(len(edges[v])):
if (dist[edges[v][i].to] >
dist[v] + edges[v][i].weight):
dist[edges[v][i].to] = dist[v] + edges[v][i].weight
if edges[v][i].weight == 0:
Q.appendleft(edges[v][i].to)
else:
Q.append(edges[v][i].to)
for i in range(V):
print(dist[i], end = " ")
print()
def addEdge(u: int, v: int, wt: int):
edges[u].append(node(v, wt))
edges[u].append(node(v, wt))
if __name__ == "__main__":
addEdge(0, 1, 0)
addEdge(0, 7, 1)
addEdge(1, 7, 1)
addEdge(1, 2, 1)
addEdge(2, 3, 0)
addEdge(2, 5, 0)
addEdge(2, 8, 1)
addEdge(3, 4, 1)
addEdge(3, 5, 1)
addEdge(4, 5, 1)
addEdge(5, 6, 1)
addEdge(6, 7, 1)
addEdge(7, 8, 1)
src = 0
zeroOneBFS(src)
C#
using System;
using System.Collections.Generic;
class ZeroOneBFS {
private class Node {
public int to;
public int weight;
public Node(int to, int wt) {
this.to = to;
this.weight = wt;
}
}
private const int numVertex = 9;
private List<Node>[] edges = new List<Node>[numVertex];
public ZeroOneBFS() {
for (int i = 0; i < edges.Length; i++) {
edges[i] = new List<Node>();
}
}
public void addEdge(int u, int v, int wt) {
edges[u].Add(new Node(v, wt));
edges[v].Add(new Node(u, wt));
}
public void zeroOneBFS(int src) {
int[] dist = new int[numVertex];
for (int i = 0; i < numVertex; i++) {
dist[i] = int.MaxValue;
}
Queue<int> queue = new Queue<int>();
dist[src] = 0;
queue.Enqueue(src);
while (queue.Count > 0) {
int v = queue.Dequeue();
for (int i = 0; i < edges[v].Count; i++) {
if (dist[edges[v][i].to] >
dist[v] + edges[v][i].weight) {
dist[edges[v][i].to] =
dist[v] + edges[v][i].weight;
if (edges[v][i].weight == 0) {
queue.Enqueue(edges[v][i].to);
} else {
queue.Enqueue(edges[v][i].to);
}
}
}
}
for (int i = 0; i < dist.Length; i++) {
Console.Write(dist[i] + " ");
}
}
static void Main(string[] args) {
ZeroOneBFS graph = new ZeroOneBFS();
graph.addEdge(0, 1, 0);
graph.addEdge(0, 7, 1);
graph.addEdge(1, 7, 1);
graph.addEdge(1, 2, 1);
graph.addEdge(2, 3, 0);
graph.addEdge(2, 5, 0);
graph.addEdge(2, 8, 1);
graph.addEdge(3, 4, 1);
graph.addEdge(3, 5, 1);
graph.addEdge(4, 5, 1);
graph.addEdge(5, 6, 1);
graph.addEdge(6, 7, 1);
graph.addEdge(7, 8, 1);
int src = 0;
graph.zeroOneBFS(src);
return;
}
}
Javascript
<script>
class Node
{
constructor(to,wt)
{
this.to = to;
this.weight = wt;
}
}
let numVertex = 9;
let edges = new Array(numVertex);
function _ZeroOneBFS()
{
for (let i = 0; i < edges.length; i++) {
edges[i] = [];
}
}
function addEdge(u,v,wt)
{
edges[u].push(edges[u].length, new Node(v, wt));
edges[v].push(edges[v].length, new Node(u, wt));
}
function zeroOneBFS(src)
{
let dist = new Array(numVertex);
for (let i = 0; i < numVertex; i++) {
dist[i] = Number.MAX_VALUE;
}
let queue = [];
dist[src] = 0;
queue.push(src);
while (queue.length!=0) {
let v = queue.shift();
for (let i = 0; i < edges[v].length; i++) {
if (dist[edges[v][i].to] >
dist[v] + edges[v][i].weight) {
dist[edges[v][i].to] =
dist[v] + edges[v][i].weight;
if (edges[v][i].weight == 0) {
queue.unshift(edges[v][i].to);
} else {
queue.push(edges[v][i].to);
}
}
}
}
for (let i = 0; i < dist.length; i++) {
document.write(dist[i] + " ");
}
}
_ZeroOneBFS();
addEdge(0, 1, 0);
addEdge(0, 7, 1);
addEdge(1, 7, 1);
addEdge(1, 2, 1);
addEdge(2, 3, 0);
addEdge(2, 5, 0);
addEdge(2, 8, 1);
addEdge(3, 4, 1);
addEdge(3, 5, 1);
addEdge(4, 5, 1);
addEdge(5, 6, 1);
addEdge(6, 7, 1);
addEdge(7, 8, 1);
let src = 0;
zeroOneBFS(src);
</script>
This problem can also be solved by Dijkstra but the time complexity will be O(E + V Log V) whereas by BFS it will be O(V+E).
This article is contributed by Ayush Jha. If you like GeeksforGeeks and would like to contribute, you can write an article using write.geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks. Please write comments if you find anything incorrect, or if you want to share more information about the topic discussed above.
Like Article
Save Article
Vote for difficulty
Current difficulty :
Medium

Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Кратчайшие пути в графе
Рассмотрим взвешенный граф, то есть у всех его ребер есть вес — некоторое число. Можно представить, что это цена, за которую мы можем по нему проехать.
Как его хранить? Давайте просто в списке смежности вместо номеров вершин соседа хранить пару (номер соседа, вес ребра до него).
Давайте решать задачу посика кратчайшего пути в графе — мы хотим за наименьшую стоимость проехать из вершины (A) в (B).
Обычно будем считать, что в графе нет циклов отрицательного веса — иначе кратчайшее расстояниие может быть равно минус бесконечности.
Для данной задачи есть несколько алгоритмов решения.
Алгоритм Флойда
Мы с вами уже знаем динамическое программирование, давайте рассмотри следующую динамику:
(d_{i j}^k) — это длина кратчайшего пути от вершины (i) до (j), используя как промежуточные только вершины из первых (k) = (d_{i j}^k) (напоминает рюкзак).
База динамики ((k = 0)) определяется только путями из одного ребра. Если есть ребро из (i) в (j) стоимостью (c), то (d_{i j}^{0}) = (c). Если таких ребер несколько, то, конечно, надо взять минимум.
Если мы хотим посчитать (d_{i j}^{k}), то у нас есть два варианта
-
Не брать на пути нигде (k)-ую вершину, тогда (d_{i j}^{k}) = (d_{i j}^{k — 1})
-
Взять где-нибудь в пути k-ую вершину, тогда путь разбивается на две части — от (i) до (k) и от (k) до (j), раз итоговый путь кратчайший, то и и эти два пути должны быть кратчайшми, а значит формула (d_{i j}^{k}) = (d_{i k}^{k — 1}) + (d_{k j}^{k — 1})
В результате ответ — (d_{A B}^{n}),
Можете подумать, как по такой динамике восстановить сам путь.
Также заметим, что вместо трехмерной динамики в этом алгоритме можно использовать двухмерную, храня в (dp_{ij}) последнее известное значение из (dp_{ij}^0), (dp_{ij}^1) (dp_{ij}^2), (ldots), (dp_{ij}^n).
for(int k = 0; k < n; k++){
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
a[i][j] = min(a[i][j], a[i][k] + a[k][j]);
}
}
}Теоретическое задание
Подумайте, как находить циклы отрицательного веса с помощью Флойда.
Плюсы алгоритма в том, что он находит расстояние сразу от всех вершин графа до остальных, а минус — алгоритм работает за (O(N^3));
Практическое задание
Первые две задачи на алгоритм Флойда.
Алгоритм Дейкстры
Для этого алгоритма придется рассматривать только графы без отрицательных рёбер.
Алгоритм Дейкстры решает немного другую задачу: он находит расстояние от одной вершины (A) до каждой вершины. Давайте для каждой вершины хранить расстояние до нее из вершины (A) в массиве (d). Например: * (d[A] = 0) * (d[x] = infty), если x не достижима из A
Назовем релаксацией обновление ответа для вершины (b) через ребро ((a, b, c)) таким способом: (d[b] = min(d[b], d[a] + c)).
- При таком действии ответ не может стать лучше, чем кратчайшее расстояние до (b), так как мы просто пользуемся путем для вершины (a) и продлеваем его в (b).
- Если мы прорелаксировали все ребра в кратчайшем пути в правильном порядке до вершины (b), то мы получим кратчайший путь до (b).
Теперь давайте каждый раз доставать вершину, для которой расстояние от А сейчас минимально, и мы еще ее не смотрели и затем обновлять всех ее соседей. Допустим вершина с минимальным расстоянием — x, тогда надо прорелаксировать все ребра из нее.
Давайте докажем корректность алгоритма по индукции:
База) Первой вершиной мы всегда рассмотрим (A), но для нее верно, что расстояние от (А) до (А) = 0;
Шаг) Мы достали вершину (i), нам известно, что для всех ее предков ответ — корректен, но тогда, допустим, что для (i)-ой вершины мы нашли ответ больший, чем надо, тогда это значит, что мы должны прийти из еще не рассмотренной вершины, но так как ребер отрицательного веса в графе нет, то такое невозможно (Rightarrow) мы доказали
https://visualgo.net/en/sssp?slide=1
Есть две возможные реализации алгоритма
- реализация помощью нахождения минимального расстояния внутри массива за линию. Так как мы для каждого шага находим минимальную вершину, то мы сделаем не более (N) шагов, но при этом на каждом шаге мы находим минимум за линию, то есть алгоритм работает за (O(N^2)).
for (int i = 0; i < n; ++i){
int uk = -1;
for (int j = 0; j < n; j++){
if ((mark[j] == 0) && ((uk == -1) || (d[j] < d[uk]))){
uk = j;
}
}
for (int j = 0; j < n; j++){
if ((j != uk) && (g[uk][j] != -1)) d[j] = min(d[j], g[uk][j] + d[uk]);
}
mark[uk] = 1;
}- Реализация за (O(MlognN + NlogN)) с помощью нахождения минимального расстояния внутри кучи/сета за логарифм. Так как для каждой вершины мы сделаем не более одного извлекания из структуры + каждое ребро мы используем максимум два раза. Для этого давайте в выбранной структуре хранить пару (расстояние, вершина); Первый код реализован с set, второй с кучей. Так как в куче нет компаратора на возрастание, то надо либо сделать свой, либо домножить расстояние на -1;
while (used.size()) {
int v = (*(used.begin())).second;
for (int i = 0; i < g[v].size(); i++) {
int to = g[v][i].first, c = g[v][i].second;
if (dist[v] + c < dist[to]) {
used.erase({dist[to], to});
dist[to] = dist[v] + to;
used.insert({dist[to], to});
}
}
used.erase({dist[v], v});
}while (!q.empty()) {
int v = q.top().second;
q.pop();
for (int j = 0; j < g[v].size(); ++j) {
int to = g[v][j].first, c = g[v][j].second;
if (d[v] + c < d[to]) {
d[to] = d[v] + c;
q.push({-d[to], to});
}
}
}Из асимптотики понятно, что при большом количестве ребер первый алгоритм писать лучше, иначе второй.
Теоретическое задание
Приведите примеры, когда каждый из алгоритмов работает лучше.
Недостаток алгоритма Дейкстры всего один — он не работает, если в графе есть ребра отрицательного веса.
Практическое задание
3-5 Задача на алгоритм Дейкстры.
Форд-Беллман
Этот алгоритм решает ту же задачу, что и Дейкстра, но зато может работать с отрицательными ребрами!
Давайте заведем массив расстояний, как и в дейкстре, для стартовой вершины расстояние = 0. Алгоритм состоит в релаксации каждого ребра в графе (N-1) раз.
Это работает потому, что в кратчайшем пути не больше, чем (N-1) ребро, и если мы прорелаксируем их в таком порядке, этот путь найдется. После (N-1) прохода по всем ребрам и их релаксации мы точно это сделаем и найдем кратчайший путь.
Также в этом случае удобнее хранить список ребер явно вместо списка смежности.
int from[m], to[m], cost[m];
for (int i = 0; i < n - 1; ++i) {
for (int j = 0; j < m; ++j) {
d[to[j]] = min(d[to[j]], d[from[j]] + cost[j]);
}
}Теоретическое задание
Подумайте, как найти цикл отрицательного веса с помощью этого алгоритма.
Практическое задание
Решите задачи 6 и 7.
Ссылка на контест
https://informatics.msk.ru/mod/statements/view.php?id=33380#1
%saved0% Граф — это (упрощенно) множество точек, называемых вершинами, соединенных какими-то линиями, называемыми рёбрами (необязательно все вершины соединены). Можно представлять себе как города, соединенные дорогами.
Любое клетчатое поле можно представить в виде графа. Вершинами будут являться клетки, а ребрами — смежные стороны клеток.
Наглядное представление о работе перечисленных далее алгоритмов можно получить благодаря визуализатору PathFinding.js.
Поиск в ширину (BFS, Breadth-First Search)
Алгоритм был разработан независимо Муром и Ли для разных приложений (поиск пути в лабиринте и разводка проводников соответственно) в 1959 и 1961 годах. Этот алгоритм можно сравнить с поджиганием соседних вершин графа: сначала мы зажигаем одну вершину (ту, из которой начинаем путь), а затем огонь за один элементарный промежуток времени перекидывается на все соседние с ней не горящие вершины. В последствие то же происходит со всеми подожженными вершинами. Таким образом, огонь распространяется «в ширину». В результате его работы будет найден кратчайший путь до нужной клетки.
Алгоритм Дейкстры (Dijkstra)
Этот алгоритм назван по имени создателя и был разработан в 1959 году. В процессе выполнения алгоритм проверит каждую из вершин графа, и найдет кратчайший путь до исходной вершины. Стандартная реализация работает на взвешенном графе — графе, у которого каждый путь имеет вес, т.е. «стоимость», которую надо будет «заплатить», чтобы перейти по этому ребру. При этом в стандартной реализации веса неотрицательны. На клетчатом поле вес каждого ребра графа принимается одинаковым (например, единицей).
А* (А «со звездочкой»)
Впервые описан в 1968 году Питером Хартом, Нильсом Нильсоном и Бертрамом Рафаэлем. Данный алгоритм является расширением алгоритма Дейкстры, ускорение работы достигается за счет эвристики — при рассмотрении каждой отдельной вершины переход делается в ту соседнюю вершину, предположительный путь из которой до искомой вершины самый короткий. При этом существует множество различных методов подсчета длины предполагаемого пути из вершины. Результатом работы также будет кратчайший путь. О реализации алгоритма читайте в здесь.
Поиск по первому наилучшему совпадению (Best-First Search)
Усовершенствованная версия алгоритма поиска в ширину, отличающаяся от оригинала тем, что в первую очередь развертываются узлы, путь из которых до конечной вершины предположительно короче. Т.е. за счет эвристики делает для BFS то же, что A* делает для алгоритма Дейкстры.
IDA* (A* с итеративным углублением)
Расшифровывается как Iterative Deeping A*. Является измененной версией A*, использующей меньше памяти за счет меньшего количества развертываемых узлов. Работает быстрее A* в случае удачного выбора эвристики. Результат работы — кратчайший путь.
Jump Point Search
Самый молодой из перечисленных алгоритмов был представлен в 2011 году. Представляет собой усовершенствованный A*. JPS ускоряет поиск пути, «перепрыгивая» многие места, которые должны быть просмотрены. В отличие от подобных алгоритмов JPS не требует предварительной обработки и дополнительных затрат памяти.
Материалы по более интересным алгоритмам мы обозревали в подборке материалов по продвинутым алгоритмам и структурам данных.
Каждому пути во взвешенном орграфе можно сопоставить вес пути (path weight) — величину, равную сумме весов ребер, составляющих этот путь. Эта важная мера позволяет сформулировать задачи наподобие » найти путь между двумя заданными вершинами, имеющий минимальный вес » . Эти задачи о кратчайших путях (shortest-path problem) и являются темой данной главы. Такие задачи не только естественно возникают во многих приложениях, но и знакомят нас с областью алгоритмов решения общих задач, применимых к широкому кругу реальных приложений.
Некоторые из рассматриваемых в данной главе алгоритмов непосредственно связаны с алгоритмами, изученными в лекциях 17-20. Здесь полностью применима наша базовая парадигма поиска на графе, а в основе решения задач о кратчайших путях лежат некоторые специальные механизмы, которые были использованы в
«Виды графов и их свойства»
и
«Орграфы и DAG-графы»
для решения задач связности в графах и орграфах.
Для краткости мы будем называть взвешенные орграфы сетями (network). На
рис.
21.1 показан пример сети и ее стандартные представления. В
«Минимальные остовные деревья»
уже был разработан интерфейс АТД сети с представлениями матрицей смежности и списками смежности. При вызове конструктора достаточно задать второй аргумент равным true, и класс будет содержать лишь одно представление каждого ребра — как при получении представлений орграфов в
«Орграфы и DAG-графы»
из представлений неориентированных графов из главы 17
«Виды графов и их свойства»
(см. программы 20.1-20.4).
Как было подробно разъяснено в
«Минимальные остовные деревья»
, при работе со взвешенными орграфами мы используем указатели на абстрактные ребра, чтобы расширить применимость полученных реализаций. У этого подхода для орграфов имеются некоторые отличия по сравнению с неориентированными графами (см.
«Минимальные остовные деревья»
). Во-первых, имеется только одно представление каждого ребра, и поэтому при использовании итератора не нужна функция from из класса edge (см. программу 20.1): в орграфе значение e->from(v) истинно для любого указателя на ребро e, возвращаемого итератором для v. Во-вторых, как было показано в
«Орграфы и DAG-графы»
, часто при обработке орграфа полезно иметь возможность работать с обратным ему графом, но сейчас нам потребуется подход, отличный от принятого в программе 19.1, поскольку там при создании обратного графа создаются ребра, а здесь предполагается, что клиенты АТД графа, предоставляющие указатели на ребра, не должны сами создавать ребра (см. упражнение 21.3).
В приложениях или системах, где могут потребоваться любые типы графов, нетрудно определить такой АТД сети, от которого можно породить АТД для невзвешенных неориентированных графов из глав 17 и 18, невзвешенных орграфов из
«Орграфы и DAG-графы»
или взвешенных неориентированных графов из
«Минимальные остовные деревья»
(см. упражнение 21.10).

Рис.
21.1.
Пример сети и ее представления
Здесь показана сеть (взвешенный орграф) и четыре ее представления: список ребер, графический вид, матрица смежности и списки смежности (слева направо). Как и для алгоритмов вычисления MST, веса указываются в элементах матрицы и в узлах списков, но в программах используются указатели на ребра. На рисунках длины ребер часто изображаются пропорциональными их весам (как и для алгоритмов вычисления MST), но мы не настаиваем на этом правиле, поскольку большинство алгоритмов поиска кратчайших путей могут работать с произвольными неотрицательными весами (хотя отрицательные веса могут усложнить ситуацию). Матрица смежности несимметрична, а списки смежности содержат по одному узлу для каждого ребра (как в невзвешенном орграфе). Несуществующие ребра представляются пустыми указателями в матрице (незаполненные места на рисунке) и вообще отсутствуют в списках. Петли нулевой длины введены для упрощения реализации алгоритмов поиска кратчайших путей. Они не представлены в списке ребер слева — для экономии места и чтобы продемонстрировать типичную ситуацию, когда они добавляются при создании представления матрицей смежности или списками смежности.
При работе с сетями обычно удобно оставлять петли во всех представлениях. При таком соглашении для указания, что никакая вершина не достижима из себя самой, в алгоритмах можно использовать сигнальный вес (с максимальным значением). В наших примерах мы будем использовать петли нулевого веса, хотя зачастую имеют смысл петли с положительным весом. Во многих приложениях также требуется наличие параллельных ребер — возможно, с различными весами. Как было сказано в
«Минимальные остовные деревья»
, в различных приложениях удобны разные варианты игнорирования или объединения таких ребер. Однако в этой главе для простоты ни в одном из наших примеров параллельные ребра не применяются, в представлении матрицей смежности параллельные ребра не допускаются, и мы выполняем проверку наличия параллельных ребер или их удаление в списках смежности.
Все свойства связности ориентированных графов, рассмотренные в
«Орграфы и DAG-графы»
, справедливы и для сетей. Только там мы выясняли, возможно ли достижение одной вершины из другой, а в этой главе мы учитываем веса и пытаемся найти наилучший путь из одной вершины в другую.
Определение 21.1. Кратчайшим путем между двумя вершинами s и t в сети называется такой направленный простой путь из s в t, что никакой другой путь не имеет меньшего веса.
Лаконичность этого определения скрывает некоторые важные моменты. Во-первых, если t не достижима из s, то не существует вообще никакого пути, поэтому нет и кратчайшего пути. Для удобства рассматриваемые алгоритмы часто трактуют этот случай как наличие между s и t пути с бесконечным весом. Во-вторых, как и в случае алгоритмов вычисления MST, в наших примерах сетей веса ребер пропорциональны их длинам,
хотя определение этого не требует, и в алгоритмах (кроме одного в разделе 21.5) это не предполагается. Вообще-то алгоритмы поиска кратчайшего пути запросто находят неочевидные обходы — например, путь между двумя вершинами, который проходит через несколько других вершин, но имеет общий вес меньше веса ребра, непосредственно соединяющего эти вершины. В-третьих, может существовать несколько путей из одной вершины в другую с одним и тем же весом — обычно достаточно найти один из них. На
рис.
21.2 показан пример, иллюстрирующий эти моменты.
В определении требуется, чтобы путь был простым, хотя для сетей, содержащих ребра с неотрицательными весами, это несущественно, поскольку в такой сети можно удалить из пути любой цикл и получить не более длинный путь (даже более короткий, если цикл не состоит из ребер с нулевым весом). Но в случае сетей с ребрами, которые могут иметь отрицательный вес, необходимость ограничиться простыми путями понятна: ведь если в сети есть цикл с отрицательным весом, то понятие кратчайшего пути теряет смысл. Например, предположим, что ребро 3-5 в сети на
рис.
21.1 имеет вес -0.38, а ребро
5-1 — вес -0.31. Тогда вес цикла 1-4-3-5-1 равен 0.32 + 0.36 — 0.38 — 0.31 = -0.01. Можно кружить по этому циклу, порождая все более короткие пути. Учтите, что не обязательно, как и в данном примере, чтобы все ребра в таком цикле имели отрицательные веса; значение имеет лишь сумма весов ребер. Для краткости ориентированные циклы с общим отрицательным весом мы будем называть отрицательными циклами.
Предположим, что в определении одна из вершин на пути из s в t принадлежит также некоторому отрицательному циклу. В этом случае существование (непростого) кратчайшего пути из s в t бессмысленно, поскольку можно использовать цикл для создания пути с весом, меньшим любого заданного значения. Чтобы избежать таких моментов, в данном определении мы ограничиваемся простыми путями — тогда понятие кратчайшего пути можно строго определить для любой сети. До раздела 21.7 мы не будем рассматривать отрицательные циклы в сетях, поскольку, как мы увидим, они представляют собой принципиальное препятствие на пути решения задачи поиска кратчайших путей.
Чтобы найти кратчайшие пути во взвешенном неориентированном графе, можно построить сеть с теми же вершинами и с двумя ребрами (по одному в каждом направлении), которые соответствуют каждому ребру в исходном графе.
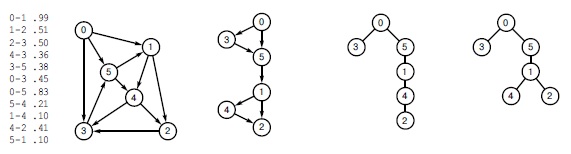
Рис.
21.2.
Деревья кратчайших путей
Дерево кратчайших путей (SPT) определяет наиболее короткие пути из корня в другие вершины (см. определение 21.2). В общем случае различные пути могут иметь одинаковую длину, поэтому может существовать несколько SPT, определяющих кратчайшие пути из заданной вершины. В сети, приведенной слева, все кратчайшие пути из 0 являются подграфами DAG-графа, показанного справа от сети. Дерево с корнем в 0 является остовом этого DAG тогда и только тогда, когда оно является SPT-деревом для вершины 0. Два таких дерева приведены справа.
Существует взаимно однозначное соответствие между простыми путями в сети и простыми путями в графе, и стоимости этих путей совпадают; значит, совпадают и задачи поиска кратчайших путей для них. При построении стандартного представления списками смежности или матрицей смежности для взвешенного неориентированного графа (см., например,
рис.
20.3) получается точно такая же сеть. Это построение бесполезно, если веса могут быть отрицательными, поскольку в сети при этом получаются отрицательные циклы, а мы не знаем, как решать задачи поиска кратчайших путей в сетях с отрицательными циклами (см. раздел 21.7). В остальных случаях алгоритмы для сетей, которые рассматриваются в этой главе, работают и для взвешенных неориентированных графов.
В некоторых приложениях удобно вместо ребер либо наряду с ребрами присваивать веса вершинам; можно также рассмотреть более сложные задачи, где имеют значение как количество ребер в пути, так и общий вес пути. Подобные задачи можно решать, приводя их к сетям со взвешенными ребрами (см., например, упражнение 21.4) или несколько расширяя базовые алгоритмы (см., например, упражнение 21.52).
Поскольку из контекста и так все понятно, мы не вводим специальную терминологию, позволяющую отличать кратчайшие пути во взвешенных графах от кратчайших путей в графах без весов (где вес пути просто равен количеству составляющих его ребер — см.
«Виды графов и их свойства»
). Общепринятая терминология относится к сетям (со взвешенными ребрами), как в данной главе, т.к. особые случаи для неориентированных или невзвешенных графов легко решаются с помощью тех же алгоритмов, что и для сетей.
Мы будем рассматривать те же базовые задачи, которые были определены в
«Поиск на графе»
для неориентированных и невзвешенных графов. Мы вновь формулируем их здесь, обращая внимание на то, что определение 21.1 неявно обобщает их, учитывая веса в сетях.
Кратчайший путь из истока в сток. Для заданных начальной вершины s и конечной вершины t нужно найти кратчайший путь в графе из s в t. Начальную вершину мы называем истоком (source), а конечную вершину — стоком (sink), за исключением тех ситуаций, где такое использование терминов противоречит другому определению истоков (вершин без входящих ребер) и стоков (вершин без исходящих ребер) в орграфах.
Кратчайшие пути из одного истока. Для заданной начальной вершины s нужно найти кратчайшие пути из s во все остальные вершины графа.

Рис.
21.3.
Все кратчайшие пути
В этой таблице приведены все кратчайшие пути в сети с
рис.
21.1 вместе с их длинами. Поскольку данная сеть является сильно связной, в ней существуют пути, соединяющие каждую пару вершин. Цель алгоритма поиска кратчайшего пути из истока в сток — вычисление одного из элементов этой таблицы; цель алгоритма поиска кратчайшего пути из одного истока — вычисление одной из строк этой таблицы; а цель алгоритма поиска кратчайших путей между всеми парами вершин — вычисление всей таблицы. Обычно мы используем более компактные представления, которые содержат по существу ту же информацию и позволяют клиентам обойти любой путь за время, пропорциональное количеству его ребер (см.
рис.
21.8).
Кратчайшие пути между всеми парами вершин. Нужно найти кратчайшие пути, соединяющие каждую пару вершин в графе. Иногда для краткости это множество V2 путей мы будем называть термином все кратчайшие пути.
Если имеется несколько кратчайших путей, соединяющих любую заданную пару вершин, мы выбираем любой из них. Поскольку пути имеют различное количество ребер, наши реализации предоставляют функции-члены, которые позволяют клиентам обходить пути за время, пропорциональное длинам путей. Любой кратчайший путь неявно содержит и собственную длину, но наши реализации выдают длины явно. Итак, уточним: в приведенных выше постановках задач выражение » найти кратчайший путь » означает » вычислить длину кратчайшего пути и способ обхода конкретного пути за время, пропорциональное его длине » .
На
рис.
21.3 показаны кратчайшие пути для сети с
рис.
21.1. В сетях с V вершинами для решения задачи с одним истоком необходимо указать V путей, а для решения задачи для всех пар вершин — V2 путей. В наших реализациях мы используем более компактное представление, чем эти списки путей; об этом уже было упомянуто в
«Поиск на графе»
и будет подробно рассказано в разделе 21.1.
В реализациях на C++ мы строим алгоритмические решения этих задач в виде реализаций АТД, позволяющих создавать эффективные клиентские программы, которые могут решать разнообразные практические задачи обработки графов. Например, как показано в разделе 21.3, мы реализуем решения задач кратчайших путей для всех пар вершин в виде конструкторов внутри классов, которые отвечают на запросы кратчайшего пути за постоянное (линейное) время. Мы также построим классы для решения задачи с одним истоком, чтобы клиенты, которым нужно вычислить кратчайшие пути из заданной вершины (или небольшого множества вершин) могли не вычислять кратчайшие пути для других вершин. Внимательное рассмотрение таких моментов и надлежащее использование изучаемых здесь алгоритмов может преодолеть разницу между эффективным решением и настолько трудоемким решением, что никакой клиент не сможет воспользоваться им.
Задачи о кратчайших путях в различных вариантах возникают в широком спектре приложений. Многие приложения допускают наглядную геометрическую интерпретацию, но многие другие обрабатывают структуры с произвольными стоимостями. Как и в случае минимальных остовных деревьев (MST, см.
«Минимальные остовные деревья»
), мы иногда будем обращаться к геометрической интерпретации, чтобы облегчить понимание алгоритмов решения этих задач — постоянно помня, что наши алгоритмы способны работать и в более общих условиях. В разделе 21.5 мы рассмотрим специализированные алгоритмы для евклидовых сетей. А в разделах 21.6 и 21.7 будет показано, что базовые алгоритмы эффективны для многочисленных приложений, в которых сети представляют абстрактную модель вычислений.
Дорожные карты. Во многих дорожных картах есть замечательная вещь — таблицы с расстояниями между всеми парами главных городов. Мы считаем, что составитель карты позаботился о том, чтобы эти расстояния кратчайшими, но это предположение не всегда верно (см., например, упражнение 21.11). Обычно такие таблицы составляются для неориентированных графов, которые можно рассматривать как сети с двунаправленными ребрами, соответствующими каждой дороге, хотя в них можно включать улицы с односторонним движением на карте города и некоторые другие аналогичные моменты. Как будет показано в разделе 21.3, нетрудно предоставлять и другую полезную информацию — например, таблицу с инструкцией о прохождении кратчайших путей (см.
рис.
21.4). Современные встроенные системы в автомобилях и других транспортных системах предоставляют такие возможности. Карты являются евклидовыми графами, и в разделе 21.4 мы рассмотрим алгоритмы поиска кратчайших путей, которые при поиске кратчайших путей учитывают позицию вершины.
Авиарейсы. Карты маршрутов и расписания для авиалиний или других транспортных систем могут быть представлены в виде сетей, для которых важны различные задачи о кратчайших путях. Например, может потребоваться минимизировать время перелета между двумя городами, или же стоимость путешествия. Стоимости в таких сетях могут включать функции от времени, финансовых затрат или других интегральных ресурсов. Например, из-за преобладающих ветров перелеты между двумя городами обычно занимают больше времени в одном направлении, чем в другом. Авиапассажиры также знают, что стоимость перелета не обязательно является простой функцией расстояния между городами — очень часто встречаются ситуации, когда окольный маршрут (с пересадками) дешевле прямого перелета. Такие усложнения могут быть обработаны базовыми алгоритмами поиска кратчайших путей, которые мы рассматриваем в этой главе; эти алгоритмы предназначены для работы с любыми положительными стоимостями.
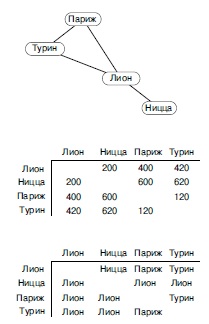
Рис.
21.4.
Расстояния и пути
Дорожные карты обычно содержат таблицы расстояний наподобие приведенной в центрери-сунка для небольшого подмножества французских городов. Соединяющие их автострады показаны в виде графа в верхней части рисунка. Может быть полезна, хотя и редко встречается на картах, таблица наподобие приведенной внизу: в ней отмечены пункты, лежащие на кратчайшем пути. Например, из этой таблицы видно, как добраться из Парижа в Ниццу: первым на пути следования должен быть Лион.
Фундаментальные вычисления кратчайших путей, предлагаемые этими приложениями — это лишь небольшая часть области применимости алгоритмов для вычисления кратчайших путей. В разделе 21.6 мы рассмотрим задачи из прикладных областей, которые с виду не имеют отношения к данной тематике. В этом нам поможет сведение — формальный механизм для доказательства связи между задачами. Мы решаем задачи для этих приложений, трансформируя их в абстрактные задачи поиска кратчайших путей, которые не имеют очевидной геометрической связи с описанными задачами. Некоторые приложения приводят к задачам о кратчайших путях в сетях с отрицательными весами. Такие задачи могут оказаться намного более трудными, чем задачи, где отрицательные веса невозможны. Задачи о кратчайших путях для таких приложений не только заполняют промежуток между элементарными алгоритмами и алгоритмически неразрешимыми задачами, но и приводят нас к мощным и общим механизмам принятия решений.
Как и в случае алгоритмов вычисления MST из
«Минимальные остовные деревья»
, мы часто смешиваем понятия веса, стоимости и расстояния. Здесь мы обычно также используем естественную геометрическую наглядность, даже работая с более общими постановками и с произвольными весами ребер. Поэтому мы говорим о » длине » путей и ребер вместо » веса » , и говорим, что один путь » короче » другого, вместо выражения » имеет меньший вес » . Мы также можем сказать, что вершина v находится » ближе » к s, чем w, вместо » ориентированный путь наименьшего веса из s в v имеет меньший вес, чем вес ориентированного пути наименьшего веса из s в w » , и т.д. Это проявляется и в стандартном использовании термина » кратчайшие пути » и выглядит естественно, даже если веса не связаны с расстояниями (см.
рис.
21.2). Однако в разделе 21.6, при расширении наших алгоритмов на отрицательные веса, от этого придется отказаться.
Эта глава организована следующим образом. После знакомства с фундаментальными принципами в разделе 21.1, в разделах 21.2 и 21.3 мы рассмотрим базовые алгоритмы для задач поиска кратчайших путей из одного истока и между всеми парами вершин. После этого в разделе 21.4 мы изучим ациклические сети (или, короче, взвешенные DAG-графы), а в разделе 21.5 — методы использования геометрических свойств для решения задачи с одним истоком и стоком в евклидовых графах. Затем в разделах 21.6 и 21.7 мы переключимся на более общие задачи, где алгоритмы поиска кратчайших путей (возможно, на сетях с отрицательными весами) будут использованы как высокоуровневое средство решения задач.
Упражнения
21.1. Пометьте следующие точки на плоскости цифрами от 0 до 5, соответственно:
(1, 3) (2, 1) (6, 5) (3, 4) (3, 7) (5, 3).
Считая длины ребер весами, рассмотрите сеть, определяемую ребрами
1-03-55-23-45-10-30-44-22-3.
Нарисуйте сеть и приведите структуру списков смежности, которая формируется программой 20.5.
21.2. Покажите в стиле
рис.
21.3 все кратчайшие пути в сети, определенной в упражнении 21.1.
21.3. Разработайте реализацию класса сети, который представляет обращение взвешенного орграфа, который определяется вставленными ребрами. Включите в реализацию конструктор » обратного копирования » , который принимает в качестве аргумента граф и использует все ребра этого графа для построения обращения.
21.4. Покажите, что для вычисления кратчайших путей в сетях с неотрицательными весами и в вершинах, и на ребрах (где вес пути определяется как сумма весов вершин и ребер на этом пути), достаточно построения АТД сети с весами только на ребрах.
21.5. Найдите в инернете какую-либо доступную большую сеть, содержащую расстояния или стоимости — возможно, географическую базу данных с информацией о дорогах, соединяющих города, либо расписания движения самолетов или поездов.
21.6. Напишите генератор разреженных случайных сетей на основе программы 17.12. Для присваивания весов ребрам определите АТД ребер случайного веса и напишите две реализации: одну для генерации равномерно распределенных весов, а другую — для нормально распределенных. Напишите клиентские программы, генерирующие разреженные случайные сети для обоих распределений весов с таким множеством значений V и E, чтобы их можно было использовать для выполнения эмпирических тестов на графах.
21.7. Напишите генератор насыщенных случайных сетей на основе программы 17.13 и генератора ребер случайного веса из упражнения 21.6. Напишите клиентские программы, генерирующие случайные сети для обоих распределений весов с таким множеством значений V и E, чтобы их можно было использовать для выполнения эмпирических тестов на графах.
21.8. Реализуйте независимую от представления сети клиентскую функцию, которая строит сеть, получая ребра с весами (пары целых чисел из диапазона от 0 до V- 1 с весами от 0 до 1) из стандартного ввода.
21.9. Напишите программу, которая генерирует V случайных точек на плоскости, затем строит сеть с (двунаправленными) ребрами, соединяющими все пары точек, расстояние между которыми не превышает заданное значение d (см. упражнение 17.74), и устанавливает вес каждого ребра равным расстоянию между концами этого ребра. Определите, каким должно быть d, чтобы ожидаемое количество ребер было равно E.
21.10. Напишите базовый класс и производные классы, реализующие абстрактные типы данных для графов, которые могут быть неориентироваными или ориентированными, взвешенными или невзвешенными и насыщенными или разреженными.
21.11. Приведенная ниже таблица из опубликованной дорожной карты содержит длины кратчайших маршрутов, соединяющих города. Найдите в таблице ошибку и исправьте ее. Составьте также таблицу в стиле
рис.
21.4, которая показывает, как проследовать по кратчайшему маршруту.
| Провиденс | Вестерли | Нью-Лондон | Норвич | |
|---|---|---|---|---|
| Провиденс | — | 53 | 54 | 48 |
| Вестерли | 53 | — | 18 | 101 |
| Нью-Лондон | 54 | 18 | — | 12 |
| Норвич | 48 | 101 | 12 | — |