Непрерывная случайная величина
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
Краткая теория
Случайная величина называется непрерывной, если ее функция
распределения
непрерывно дифференцируема. В этом случае
имеет производную, которую обозначим через
– плотность распределения вероятностей.
Плотностью распределения вероятностей непрерывной случайной
величины
называются функцию
– первую производную от функции распределения
:
Из этого определения следует, что функция распределения является
первообразной для плотности распределения.
Заметим, что для описания распределения вероятностей дискретной
случайной величины плотность распределения неприменима.
Вероятность того, что непрерывная случайная величина
примет значение, принадлежащее интервалу
равна определенному интегралу от плотности
распределения, взятому в пределах от
до
.
Зная плотность распределения
,
можно найти функцию распределения
по формуле:
Числовые характеристики непрерывной случайной величины
Математическое ожидание непрерывной случайной величины
,
возможные значения которой принадлежат всей оси
,
определяется равенством:
где
– плотность распределения случайной величины
.
Предполагается, что интеграл сходится абсолютно.
В частности, если все возможные значения принадлежат интервалу
,
то:
Все свойства математического ожидания, указанные для
дискретных случайных величин, сохраняются и для непрерывных величин.
Дисперсия непрерывной случайной величины
,
возможные значения которой принадлежат всей оси
,
определяется равенством:
или равносильным равенством:
В частности, если все возможные значения
принадлежат интервалу
,
то
или
Все свойства дисперсии, указанные для дискретных случайных
величин, сохраняются и для непрерывных случайных величин.
Среднее квадратическое отклонение
непрерывной случайной величины определяется так же, как и для дискретной
величины:
При решении задач, которые выдвигает практика, приходится
сталкиваться с различными распределениями непрерывных случайных величин.
Основные законы распределения непрерывных случайных величин
- Нормальный закон распределения СВ
- Показательный закон распределения СВ
- Равномерный закон распределения СВ
Примеры решения задач
Пример 1
Дана
функция распределения F(х) непрерывной случайной величины
Х.
Найти плотность распределения вероятностей f(x), математическое ожидание M(X), дисперсию D(X) и вероятность попадания X на отрезок [a,b]. Построить графики функций F(x) и f(x).
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Плотность
распределения вероятностей:
Математическое
ожидание:
Дисперсию
можно найти по формуле:
Вероятность
попадания на отрезок:
Построим графики функций F(x) и f(x).
График плотности
распределения
График функции
распределения
Пример 2
Случайная величина Х задана плотностью вероятности
Определить константу c, математическое ожидание, дисперсию, функцию распределения величины X, а также вероятность ее попадания в интервал [0;0,25].
Решение
Константу
определим,
используя свойство плотности вероятности:
В нашем случае:
Найдем математическое
ожидание:
Найдем дисперсию:
Искомая дисперсия:
Найдем функцию
распределения:
для
:
для
:
для
:
Искомая функция
распределения:
Вероятность попадания
в интервал
:
Пример 3
Плотность
распределения непрерывной случайной величины
имеет вид:
Найти:
а)
параметр
;
б)
функцию распределения
;
в)
вероятность попадания случайной величины
в интервал
г)
математическое ожидание
и дисперсию
д)
построить графики функций
и
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
а)
Постоянный параметр
найдем из
свойства плотности вероятности:
В нашем
случае эта формула имеет вид:
б)
Функцию распределения
найдем из
формулы:
Учитывая
свойства
, сразу можем отметить,
что:
Остается
найти выражение для
, когда
принадлежит
интервалу
:
Получаем:
в)
Вероятность
попадания случайной величины
в интервал
:
г)
Математическое ожидание находим по формуле:
Для
нашего примера:
Дисперсию
можно найти по формуле:
Среднее
квадратическое отклонение равно квадратному корню из дисперсии:
д) Построим графики
и
:
График плотности вероятности f(x)
График функции распределения F(x)
Задачи контрольных и самостоятельных работ
Задача 1
НСВ на всей
числовой оси oX задана интегральной функцией:
Найти
вероятность, что в результате 2 испытаний случайная величина примет значение,
заключенное в интервале (0;4).
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 2
Дана
дифференциальная функция непрерывной СВ Х. Найти: постоянную С, интегральную
функцию F(x).
Задача 3
Случайная
величина Х задана функцией распределения F(x):
а) Найти
плотность вероятности СВ Х — f(x).
б) Построить графики
f(x), F(x).
в) Найти вероятность
попадания НСВ в интервал (0; 3).
Задача 4
Дифференциальная
функция НСВ Х задана на всей числовой оси ОХ:
Найти:
а) постоянный
параметр С=const;
б) функцию
распределения F(x);
в) вероятность
попадания в интервал -4<X<4;
г) построить
графики f(x), F(X).
Задача 5
Случайная величина
Х задана функцией распределения F(x):
а) Найти
плотность вероятности СВ Х — f(x).
б) Построить
графики f(x), F(x).
в) Найти
вероятность попадания НСВ в интервал (0;π⁄2).
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 6
НСВ X имеет
плотность вероятности (закон Коши)
а) постоянный
параметр С=const;
б) функцию
распределения F(x);
в) вероятность
попадания в интервал -1<X<1;
г) построить
графики f(x), F(X).
Задача 7
Случайная
величина X задана интегральной F(x) или дифференциальной f(x)
функцией. Требуется:
а) найти
параметр C;
б) при
заданной интегральной функции F(x) найти дифференциальную
функцию f(x), а при заданной дифференциальной функции f(x) найти интегральную
функцию F(x);
в)
построить графики функций F(x) и f(x);
г) найти
математическое ожидание M(X), дисперсию D(X) и
среднее квадратическое отклонение σ(X);
д)
вычислить вероятность попадания в интервал P(a≤x≤b);
е)
определить, квантилем какого порядка является точка xp;
ж)
вычислить квантиль порядка p
Задание 8
Дана
интегральная функция распределения случайной величины X. Найти дифференциальную
функцию распределения, математическое ожидание M(X), дисперсию D(X) и
среднее квадратическое отклонение.
Задача 9
Случайная
величина X задана интегральной функцией распределения
Найти
дифференциальную функцию, математическое ожидание и дисперсию X.
Задача 10
СВ Х
задана функцией распределения F(x). Найдите вероятность
того, что в результате испытаний НСВ Х попадет в заданный интервал (0;0,5).
Постройте график функции распределения. Найдите плотность вероятности НСВ Х и
постройте ее график. Найдите числовые
характеристики НСВ Х, если
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
В примерах в данной статье данные генерятся при каждой загрузке страницы. Если Вы хотите посмотреть пример с другими значениями —
обновите страницу .
Параметры дискретного закона распределения
В статье описано как найти среднее значение и стандартное отклонение. Вы узнаете, что такое квантиль и каких он бывает видов, а также,
как построить доверительный интервал.
Математическое описание
Смотря на закон распределения, мы можем понять, какова вероятность того или иного события,
можем сказать, какова вероятность, что произойдёт группа событий, а в этой статье мы рассмотрим, как наши выводы «на глаз» перевести
в математически обоснованное утверждение.
Крайне важное определение: математическое ожидание — это площадь под графиком распределения. Если мы говорим о дискретном распределении —
это сумма событий умноженных на соответсвующие вероятности, также известно как момент:
(2) E(X) = Σ(pi•Xi) E — от английского слова Expected (ожидание)
Для математического ожидания справедливы равенства:(3) E(X + Y) = E(X) + E(Y)
(4) E(X•Y) = E(X) • E(Y)
Момент степени k:
(5) νk = E(Xk)
Центральный момент степени k:
(6) μk = E[X — E(X)]k
Среднее значение
Среднее значение (μ) закона распределения — это математическое ожидание случайной величины
(случайная величина — это событие), например, сколько в среднем посетителей заходит в магазин в час:
| Кол-во посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Количество наблюдений | 192 | 32 | 60 | 43 | 12 | 0 | 61 |
| Таблица 1. Количество посетителей в час |
График 1. Количество посетителей в час
Чтобы найти среднее значение всех результатов необходимо сложить всё вместе и разделить на количество результатов:
μ = (192 • 0 + 32 • 1 + 60 • 2 + 43 • 3 + 12 • 4 + 0 • 5 + 61 • 6) / 400 = 695/400 = 1.74
То же самое мы можем проделать используя формулу 2:
μ = M(X) = Σ(Xi•pi) = 0 • 0.48 + 1 • 0.08 + 2 • 0.15 + 3 • 0.11 + 4 • 0.03 + 5 • 0 + 6 • 0.15 = 1.74 Момент первой степени, формула (5)
Собственно, формула 2 представляет собой среднее арифметическое всех значений
Итог: в среднем, 1.74 посетителя в час
| Количество посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Вероятность (%) | 48 | 8 | 15 | 10.8 | 3 | 0 | 15.3 |
| Таблица 2. Закон распределения количества посетителей |
Отклонение от среднего
Посмотрите на это распределение, можно предположить, что в среднем случайная величина равна 100±5, поскольку
кажется, что таких значений несравнимо больше чем тех, что меньше 95 или больше 105:
График 2. График функции вероятности. Распределение ≈ 100±5
Среднее значение по формуле (2): μ = 99.95, но как посчитать, насколько далеко все значения находятся от среднего? Вам должна быть
знакома запись 100±5. Что бы получить это значение ±, нам необходимо определить диапазон значений вокруг среднего. И мы могли бы
использовать в качестве меры удалённости «разность» между средним и случайными величинами:
(7) xi — μ
но сумма таких расстояний, а следовательно и любое производное от этого числа, будет равно нулю, поэтому в качестве меры выбрали квадрат разниц
между величинами и средним значением:
(8) (xi — μ)2
Соответственно, среднее значение удалённости — это математическое ожидание квадратов удалённости:
(9) σ2 = E[(X — E(X))2]
Поскольку вероятности любой удалённости равносильны — вероятность каждого из них — 1/n, откуда:
(10) σ2 = E[(X — E(X))2] = ∑[(Xi — μ)2]/n
Она же формула центрального момента (6) второй степени
σ возведена в квадрат, поскольку вместо расстояний мы взяли квадрат расстояний. σ2 называется дисперсией. Корень из дисперсии
называется средним квадратическим отклонением, или среднеквадратическим отклоненим, и его используют в качестве меры разброса:
(11) μ±σ
(12) σ = √(σ2) = √[∑[(Xi — μ)2]/n]
Возвращаясь к примеру, посчитаем среднеквадратическое отклонение для графика 2:
σ = √(∑(x-μ)2/n) = √{[(90 — 99.95)2 + (91 — 99.95)2 + (92 — 99.95)2 + (93 — 99.95)2 + (94 — 99.95)2 + (95 — 99.95)2 + (96 — 99.95)2 + (97 — 99.95)2 + (98 — 99.95)2 + (99 — 99.95)2 + (100 — 99.95)2 + (101 — 99.95)2 + (102 — 99.95)2 + (103 — 99.95)2 + (104 — 99.95)2 + (105 — 99.95)2 + (106 — 99.95)2 + (107 — 99.95)2 + (108 — 99.95)2 + (109 — 99.95)2 + (110 — 99.95)2]/21} = 6.06
Итак, для графика 2 мы получили:
X = 99.95±6.06 ≈ 100±6 , что немного отличается от полученного «на глаз»
Квантиль
График 3. Функция распределения. Медиана
График 4. Функция распределения. 4-квантиль или квартиль
График 5. Функция распределения. 0.34-квантиль
Для анализа функции распределения ввели понятие квантиль. Квантиль — это случайная величина при заданном уровне вероятности, т.е.:
квантиль для уровня вероятности 50% — это случайная величина на графике плотности вероятности, которая имеет вероятность 50%.
На примере с графиком 3, квантиль уровня 0.5 = 99 (ближайшее значение, поскольку распределение дискретно и события со значением 99.3 просто не существует)
- 2-квантиль — медиана
- 4-квантиль — квартиль
- 10-квантиль — дециль
- 100-квантиль — перцентиль
То есть, если мы говорим о дециле (10-квантиле), то это означает, что мы разбили график на 10 частей, что соответствует девяти линяям,
и для каждого дециля нашли значение случайной величины.
Также, используется обозначение x-квантиль, где х — дробное число, например, 0.34-квантиль, такая запись означает значение случайной величины при
p = 0.34.
Для дискретного распределения квантиль необходимо выбирать следующим образом: квантиль гарантирует вероятность, поэтому, если рассчитанный
квантиль не совпадает с одним и значений, необходимо выбирать меньшее значение.
Построение интервалов
Квантили используют для построения доверительных интервалов, которые необходимы для исследования статистики не одного конкретного события (например,
интерес — случайное число = 98), а для группы событий (например, интерес — случайное число между 96 и 99). Доверительный интервал бывает двух видов:
односторонний и двусторонний. Параметр доверительного интервала — уровень доверия. Уровень доверия означает процент событий, которые можно считать успешными.
Двусторонний доверительный интервал
Двусторонний доверительный интервал строится следующим образом: мы задаёмся уровнем значимости, например, 10%, и выделяем область на графике так, что 90% всех
событий попадут в эту область. Поскольку интервал двусторонний, то мы отсекаем по 5% с каждой стороны, т.е. мы ищем 5й перцентиль, 95й перцентиль и значения
случайной величины между ними будут являться доверительной областью, значения за пределами доверительной области называются «критическая область»
График 6. Плотность вероятности
График 7. Функция распределения с 5 и 95 перцентилями. Цветом выделен доверительный интервал с уровнем доверия 0.9
График 8. Функция вероятности и двусторонний доверительный интервал с уровнем доверия 90%
Доверительный интервал
Левосторонний и правосторонний доверительные интервалы строятся аналогично двустороннему: для левостороннего интервала мы находим перцентиль уровня
[‘один’ минус ‘уровень значимости’]. Таким образом, для построения доверительного левостороннего интервала уровня значимости 4% нам необходимо найти четвёртый перцентиль
и всё, что справа — доверительный интервал, всё что слева — критическая область.
График 9. Левосторонний доверительный интервал с уровнем значимости 4%. Заливкой выделен доверительный интервал
График 10. Правосторонний доверительный интервал с уровнем значимости 4%. Заливкой выделен доверительный интервал
Итого
Среднее значение — математическое ожидание случайной величины, находится по формуле:
μ = E(X) = Σ(pi•Xi)
Среднеквадратичное отклонение — математическое ожидание удалённости значений от среднего, находится по формуле:
σ = √(σ2) = √[∑[(Xi — μ)2]/n]
n-квантиль — разделение функции распределения на n равных отрезков, основные типы квантилей:
- 2-квантиль — медиана
- 4-квантиль — квартили
- 10-квантиль — децили
- 100-квантиль — перцентили
Доверительный интервал уровня α — участок функции вероятности, содержащий α всех возможных значений. Двусторонний доверительный
интервал строится отсечением (1-α)/2 справа и слева. Левосторонний и правосторонний доверительные интервалы строятся отсечением
области (1-α) слева и справа соответственно.
Построить ряд распределения
Предположим, мы имеем 100 значений и все разные, например: масса тела Сомалийских пиратов.
Такой набор данных обрабатывать неудобно, мы даже не можем представить их на обычном графике.
Поэтому нам необходимо категоризировать имеющиеся данные и для этого мы делаем следующее:
Запишем наши данные в таблицу:
| 90 | 63 | 96 | 82 | 82 | 105 | 60 | 83 | 93 | 65 |
| 112 | 79 | 65 | 104 | 105 | 83 | 85 | 99 | 70 | 109 |
| 108 | 92 | 111 | 73 | 69 | 81 | 68 | 81 | 63 | 92 |
| 76 | 91 | 96 | 97 | 57 | 59 | 90 | 65 | 86 | 74 |
| 103 | 57 | 90 | 82 | 98 | 111 | 71 | 87 | 110 | 108 |
| 97 | 91 | 80 | 73 | 83 | 84 | 85 | 66 | 105 | 63 |
| 81 | 96 | 98 | 108 | 114 | 71 | 105 | 57 | 101 | 98 |
| 98 | 90 | 95 | 67 | 78 | 107 | 90 | 114 | 70 | 103 |
| 111 | 59 | 82 | 87 | 65 | 98 | 74 | 114 | 56 | 110 |
| 111 | 102 | 88 | 91 | 102 | 104 | 84 | 92 | 56 | 102 |
| Таблица 3. Вес сомалийских пиратов |
Данные разобьём на группы, для начала предлагаю разбить на десять интервалов:
Узнаём максимальное и минимальное значения, вычитаем их друг из друга и делим на количество
интервалов — получили отрезки:
Максимальное значение: 114
Минимальное значение: 56
Разница: 114 — 56 = 58
Длина интервала: 58 / 10 = 5.8
Теперь посчитаем количество пиратов (весов, я имею ввиду) в каждом интервале:
| # | Интервал | Количество элементов |
|---|---|---|
| 1. | 56 — 61.8 | 8 |
| 2. | 61.8 — 67.6 | 9 |
| 3. | 67.6 — 73.4 | 8 |
| 4. | 73.4 — 79.2 | 5 |
| 5. | 79.2 — 85 | 13 |
| 6. | 85 — 90.8 | 11 |
| 7. | 90.8 — 96.6 | 11 |
| 8. | 96.6 — 102.4 | 12 |
| 9. | 102.4 — 108.2 | 12 |
| 10. | 108.2 — 114 | 8 |
| Таблица 4. Количество элементов в интервалах |
Вуа-ля, наше распределение на графике:
График 11. Ряд распределения массы тела сомалийских пиратов
Бонус
Интервалы лучше брать целыми числами, поэтому, если с выбранным количеством интервалов
размер выходит нецелым, то можно раздвинуть диапазон значений, пример:
Значение интервала равно 5.8, число не является целым, поэтому
отодвигаем верхнюю границу:
Остаток от деления: [(114 — 56) / 10] = 8
Подвинуть на: 2
Новый диапазон: [56;116]
Диапазон можно двигать как вверх, так и вниз, но лучше в обе стороны.
Совет
Принято делить распределение на 7-8 интервалов, но в каждой конкретной ситуации
Вы можете выбрать отличное количество интервалов, впрочем, как и сделать их
различной длины.
Список параметров
Итак, вот список основных параметров дискретного закона распределения:
| Название | Символ | Формула |
|---|---|---|
| Математическое ожидание (среднее) | E(X) | Σ(pi•Xi) |
| Центральный момент (среднеквадратичное отклонение) |
σx | σ = √(σ2) = √[∑[(Xi — μ)2]/n] |
| Длина интервала | R | max(x) — min(x) |
| Мода | mo | max P(x = mo) |
| 1й квантиль | — | F(x) = 0.25 |
| Медиана | me | F(x) = 0.5 |
| Дециль | — | F(x) = 0.1 |
| Таблица 5. Основные параметры дискретного закона распределения |
Шаблон гистограммы в OpenOffice Calc
Файл histogram_mock.ods содержит шаблон
построения гистограммы.
Вам понравилась статья?
/
Просмотров: 16 086
Предлагаю вашему вниманию адаптированный перевод главы книги OnlineStatBook посвященной нормальным распределениям.
Вводный раздел определяет, что значит для распределения быть нормальным и представляет некоторые важные свойства нормального распределения. Интересная история открытия нормального распределения описана во втором разделе. Методы вычисления вероятностей, основанные на нормальном распределении, описаны в разделе «Области нормального распределения». «Разновидности нормального распределения» позволяет вам вводить значения среднего и стандартного отклонения нормального распределения и строить графики получившегося распределения. Часто используемое нормальное распределение, называемое стандартным нормальным распределением, описывается в одноименном разделе. Биномиальное распределение может быть аппроксимировано нормальным. Раздел «Нормальное приближение к биномиальному распределению» показывает это приближение. Демонстрация аппроксимации нормальным распределением позволяет вам исследовать точность этого приближения.
Введение
Нормальное распределение является наиболее важным и широко используемым распределением в статистике. Его иногда называют «колоколообразной кривой», хотя музыкальные качества такого колокола были бы не так приятны. Также его называют «распределением Гаусса» в честь математика Карла Фридриха Гаусса. Как вы увидите в разделе об истории нормального распределения, хотя Гаусс играл в ней важную роль, впервые обнаружил нормальное распределение Абрахам де Муавр.
Строго говоря, некорректно говорить о «нормальном распределении» поскольку существует много нормальных распределений. Нормальные распределения могут отличаться своими средними и стандартными отклонениями. На рис. 1 три нормальных распределения. У зеленого (самого левого) среднее равно -3, а стандартное отклонение 0.5, у красного распределения (посередине) среднее равно 0, а стандартное отклонение 1, и у черного распределение (справа) среднее равно 2 а стандартное отклонение 3. Эти, как и все другие нормальные распределения являются симметричными с относительно большими значениями в центре распределения и меньшими значениями в хвостах.
Плотность нормального распределения (высота для данного значения на оси x) показана ниже. Нормальное распределение определяется параметрами (mu) и (sigma) являющимися средним и стандартным отклонением соответственно. Символ (e) это основание натурального логарифма, а (pi) это константа пи.
$$
frac{1}{sqrt{2pisigma^2}} e^{frac{-(x-mu)^2}{2sigma^2}}
$$
Поскольку мы не будем углубляться в математическую трактовку статистики, не беспокойтесь, если это выражение вас смущает. Мы не будем возвращаться к нему в следующих разделах.
Семь свойств нормального распределения указаны ниже. Эти свойства будут более подробно проиллюстрированы в следующих разделах этой главы.
- Нормальные распределения симметричны относительно своих средних.
- Среднее значение, мода и медиана нормального распределения совпадают.
- Площадь под нормальным распределением равна 1.
- Нормальные распределения плотнее в центре и менее плотны в хвостах.
- Нормальные распределения определяются двумя параметрами: среднее (m) и стандартное отклонение (s).
- 68% площади нормального распределения находится в пределах одного стандартного отклонения от среднего.
- Примерно 95% площади нормального распределения находится в пределах двух стандартных отклонений от среднего.
История нормального распределения
В главе посвященной вероятности мы увидели, что биномиальное распределение можно использовать для таких проблем, как: «Если подбросить честную монету 100 раз, какова вероятность выпадения 60 и более орлов?» Вероятность выпадения ровно x орлов за N подбрасываний рассчитывается по формуле:
$$
P(X) = frac{N!}{x!(N-x!)}p^x(1-p)^{N-x}
$$
Где (x) это число орлов (60), (N) – количество подбрасываний монеты (100), а (p) это вероятность выпадения орла (0.5). Таким образом, чтобы решить эту проблему вам нужно вычислить вероятность 60 орлов, затем вероятность 61 орла, 62 и т.д. и сложить эти вероятности. Представьте, сколько времени потребовалось бы для вычисления биномиальных вероятностей до появления калькуляторов и компьютеров.
Абрахам де Муавр, статистик 18-го века и консультант азартных игроков, часто привлекался к проведению этих длительных вычислений. Де Муавр заметил, что, когда число событий (подбрасываний монет) увеличивается, форма биномиального распределения приближается к очень плавной кривой. Биномиальное распределение для 2, 4 и 12 подбрасываний показаны на рис. 2.
Де Муавр рассуждал, что, если бы он мог найти математическое выражение для этой кривой, он мог бы гораздо легче решать такие проблемы, как нахождение вероятности 60 и более орлов из 100 бросков монет. В точности это он и сделал, и кривая, которую он открыл, теперь называется «нормальной кривой».
Важность нормальной кривой обусловлена тем, что распределения многих природных явлений, по крайней мере приблизительно, нормально распределены. Одно из первых применений нормального распределения было к анализу ошибок измерений, сделанных при астрономических наблюдениях, ошибок произошедших из-за несовершенства инструментов и наблюдателей. Галилео в 17 веке отметил, что эти ошибки были симметричными и что небольшие ошибки возникали чаще, чем большие. Это привело к нескольким гипотезам о распределении ошибок, но только в начале 19-го века было установлено, что эти ошибки соответствуют нормальному распределению. Независимо друг от друга математики Адрейн в 1808 г. и Гаусс в 1809 г. разработали формулу для нормального распределения и показали, что ошибки хорошо соответствуют этому распределению.
Это же распределение было обнаружено Лапласом в 1778 г., когда он вывел чрезвычайно важную центральную предельную теорему, тему одного из следующих разделов. Лаплас показал, что даже если распределение не является нормальным, средние повторяющихся выборок из распределения будут распределены почти нормально, и чем больше размер выборки, тем ближе к нормальному будет распределение средних.
Большинство статистических процедур для проверки между средними значениями предполагают нормальное распределение. Поскольку распределение средних близко к нормальному, эти тесты работают хорошо даже если само распределение только приблизительно нормально. Кетле был первым, кто применил нормальное распределение к человеческим характеристикам. Он отметил, что такие характеристики, как рост, вес и сила были нормально распределены.
Площади нормального распределения
Площади под кусками нормального распределения могут быть вычислены с использованием математического анализа. Поскольку это нематематический подход к статистике, мы будем полагаться на компьютерные программы и таблицы для определения этих областей. На рис. 4 показано нормальное распределение со средним значением 50 и стандартным отклонением 10. Затененная область между 40 и 60 содержит 68% распределения.
На рис. 5 изображено нормальное распределение со средним равным 100 и стандартным отклонением 20. Как и на рис. 4, 68% распределения лежит в пределах одного стандартного отклонения от среднего.
Нормальные распределения показанные на рис. 4 и 5 это частные случаи общего правила о том, что 68% площади любого стандартного распределения находится в пределах одного стандартного отклонения от среднего.
На рис. 6 изображено нормальное распределение со средним 75 и стандартным отклонением 10. Закрашенная область содержит 95% площади и находится между 55.4 и 94.6. Для всех нормальных распределений 95% площади находится в пределах 1.96 стандартного отклонения. Для быстрых приближений иногда полезно округлять и использовать 2 вместо 1.96, в качестве числа стандартных отклонений, на которые вам нужно отступить от среднего, чтобы охватить 95% площади.
Для вычисления площадей под нормальным распределением может быть использован следующий нормальный калькулятор. Например, вы можете использовать его, чтобы найти пропорцию части нормального распределения со средним 90 и стандартным отклонением 12, которая больше 100. Установите среднее равным 90, стандартное отклонение – 12. Затем введите 110 в ячейку справа от кнопки «Above». Внизу экрана вы увидите, что закрашенная область равна 0.0478. Посмотрите сможете ли вы использовать калькулятор, чтобы узнать, что площадь между 115 и 120 равна 0.0124.
Скажем, вы хотите найти оценку, соответствующую 75-му перцентилю нормального распределения со средним значением 90 и стандартным отклонением 12. Используя обратный нормальный калькулятор, введите параметры, как показано на рис. 8, и обнаружьте, что площадь ниже 98.09 равна 0.75.
Стандартное нормальное распределение
Как обсуждалось во вводном разделе, у нормальных распределений не обязательно одинаковые средние и стандартные отклонения. Нормальное распределение со средним равным 0 и стандартным отклонением 1 называется стандартным нормальным распределением.
Области нормального распределения часто представлены таблицами стандартного нормального распределения. Часть таблицы стандартного нормального распределения показана в таблице 9.
| Z | Площадь под |
| -2.5 | 0.0062 |
| -2.49 | 0.0064 |
| -2.48 | 0.0066 |
| -2.47 | 0.0068 |
| -2.46 | 0.0069 |
| -2.45 | 0.0071 |
| -2.44 | 0.0073 |
| -2.43 | 0.0075 |
| -2.42 | 0.0078 |
| -2.41 | 0.008 |
| -2.4 | 0.0082 |
| -2.39 | 0.0084 |
| -2.38 | 0.0087 |
| -2.37 | 0.0089 |
| -2.36 | 0.0091 |
| -2.35 | 0.0094 |
| -2.34 | 0.0096 |
| -2.33 | 0.0099 |
| -2.32 | 0.0102 |
Первый столбец «Z» содержит значения стандартного нормального отклонения; второй столбец показывает значение площади левее Z. Поскольку среднее распределения равно нулю, а стандартное отклонение 1, в столбец Z равен числу стандартных отклонений левее (или правее) среднего значения. Например, Z равное -2.5 представляет значение равное 2.5 стандартных отклонений левее среднего. Площадь левее Z равна 0.0062.
Ту же информацию можно получить с помощью следующего калькулятора. На рис. 10 показано, как его можно использовать для вычисления площади левее значения -2,5 для стандартного нормального распределения. Обратите внимание, что среднее значение установлено на 0, а стандартное отклонение установлено на 1.
Значение из любого нормального распределения может быть преобразовано в соответствующее значение в стандартном нормальном распределении при помощи следующей формулы:
$$
Z = frac{(X-mu)}{sigma}
$$
где (Z) это значение стандартного нормального распределения, (X) – значение исходного распределения, (mu) — среднее исходного распределения, а (sigma) — стандартное отклонение исходного распределения.
В качестве простого упражнения, какая часть нормального распределения со средним значением 50 и стандартным отклонением 10 меньше 26? Применяя формулу, получаем:
$$
Z = (26 – 50)/10 = -2.4
$$
Из таблицы 9, мы знаем, что 0.0082 распределения левее -2.4. Нет необходимости преобразовывать значение к (Z) если вы используете апплет как показано на рис. 11.
Если все значения распределения преобразовать в (Z) значения, то у распределения будет среднее 0 и стандартное отклонение 1. Процесс преобразования распределения к стандартному со средним 0 и отклонением 1 называется стандартизацией распределения.
Приближение биномиального распределения нормальным
В разделе об истории нормального распределения мы видели, что нормальное распределение можно использовать для аппроксимации биномиального распределения. В этом разделе показывается, как рассчитать эти приближения.
Давайте начнем с примера. Пусть у вас есть честная монета, и вы хотите знать вероятность выпадения 8 орлов за 10 бросков. У биномиального распределения есть среднее равное
(mu = Np = 10*0.5 = 5) и дисперсия (sigma^2 = Np(1-p) = 10*0.5*05 = 2.5). Стандартное отклонение при этом равно 1.5811. Результат 8 орлов равен ((8 — 5)/1.5811 = 1.897) стандартных отклонений правее среднего распределения. «Какова вероятность получения значения в точности равного 1.897 стандартных отклонений правее среднего?» Вы можете удивиться, но ответ равен 0. Вероятность любой отдельной точки равна 0. Проблема в том, что биномиальное распределение является дискретным вероятностным распределением, тогда как нормальное распределение непрерывно.
Решение состоит в том, чтобы округлить и рассмотреть все значения от 7.5 до 8.5, для получения результат 8 орлов. Используя этот подход, мы вычисляем площадь под нормальной кривой от 7.5 до 8.5. Зона зеленого цвета на рис. 12 является приблизительной вероятностью получения 8 орлов.
Решение состоит в том, чтобы вычислить эту площадь. Сначала мы вычисляем площадь левее 8.5, а затем вычитаем из нее площадь левее 7,5.
Результаты использования калькулятора площади нормального распределения для определения области ниже 8.5 показаны на рисунке 13. Результаты для 7.5 показаны на рисунке 14.
Разница между площадями составляет 0.044, что является приближением биномиальной вероятности. Для этих параметров приближение очень точное.
Если у вас не было калькулятора площади нормального распределения, вы могли бы найти решение с помощью таблицы стандартного нормального распределения (таблица 9) следующим образом:
- Найти значение (Z) для 8.5, используя формулу (Z = (8.5 — 5) / 1.5811 = 2.21).
- Найти площадь левее (Z) равного 2.21 (= 0,987).
- Найти значение (Z) для 7.5, используя формулу (Z = (7.5 — 5) / 1,5811 = 1.58).
- Найти площадь левее (Z) 1.58 (= 0.943).
- Вычесть значение на шаге 4 из значения на шаге 2, и получить 0.044.
Та же логика применяется при расчете вероятности диапазона результатов. Например, чтобы рассчитать вероятность от 8 до 10 подбрасываний, вычислите площадь от 7.5 до 10.5.
Точность аппроксимации зависит от значений (N) и (p). Эмпирическое правило заключается в том, что аппроксимация хороша, если оба значения (Np) и (N (1-p)) больше 10.
Статистическая грамотность
Анализ рисков часто основан на предположении о нормальном распределении. Критики говорят, что экстремальные явления в действительности происходят чаще, чем можно было бы ожидать, если бы они были нормальными. Предположение даже было названо «большим интеллектуальным мошенничеством».
Недавняя статья, в которой обсуждается, как защитить инвестиции от экстремальных явлений, названных «риск хвоста» и определяемых как «риск хвоста, или экстремальный шок для финансовых рынков, технически определяется как инвестиция, которая двигается на более трех стандартных отклонений от среднего значения нормального распределения возврата инвестиций.»
Риск хвоста можно оценить, предполагая нормальность распределение и вычисляя вероятность такого события. Так ли следует оценивать «риск хвоста»?
События более трех стандартных отклонений от среднего значения очень редки для нормальных распределений. Однако они не так редки для других распределений, например с сильным перекосом. Если нормальное распределение используется для оценки вероятности событий хвоста, определенных таким образом, то «риск хвоста» будет недооценен.
Числовые характеристики распределения вероятностей. Математическое ожидание, дисперсия и стандартное отклонение
- Закон распределения дискретной случайной величины
- Математическое ожидание
- Дисперсия
- Среднее квадратичное отклонение
- Правило трёх сигм
- Примеры
п.1. Закон распределения дискретной случайной величины
Законом распределения дискретной случайной величины называют соответствие между полученными на опыте значениями этой величины X= {xi} и их вероятностями pi = P(xi).
При этом сумма всех вероятностей равна 1: (mathrm{sum_{i=1}^n p_i=1})
Закон распределения можно задать таблицей, графиком или аналитически (в виде формулы).
Например:
Закон распределения случайной величины X = {0;1;2;3}, равной числу выпадения орлов при 3 бросках монеты, аналитически задаётся формулой: $$ mathrm{ p_i=P(x_i)=P_3(i)=frac{C_3^{i}}{2^3}, i={0;1;2;3} } $$
В табличном виде:
|
xi |
pi |
|
0 |
1/8 |
|
1 |
3/8 |
|
2 |
3/8 |
|
3 |
1/8 |
В виде графика:

п.2. Математическое ожидание
Математическое ожидание дискретной случайной величины X = {xi} равно сумме произведений всех возможных значений xi на соответствующие вероятности pi: $$ mathrm{ M(X)=x_1p_1+x_2p_2+…+x_{n}p_{n}=sum_{i=1}^n x_{i}p_{i} } $$ Математическое ожидание является средним значением величины X.
Свойства математического ожидания
1) Размерность математического ожидания равна размерности случайной величины.
2) Математическое ожидание может быть любым действительным числом: положительным, равным 0, отрицательным.
3) Математическое ожидание постоянной величины равно этой постоянной:
M(C) = C
4) Математическое ожидание суммы независимых случайных величин равно сумме математических ожиданий:
M(X + Y) = M(X) + M(Y)
5) Математическое ожидание произведения двух независимых случайных величин равно произведению математических ожиданий:
M(XY) = M(X) · M(Y)
6) Постоянный множитель можно вынести за знак математического ожидания:
M(CX) = C · M(X)
Например:
Пусть в результате экспериментов получено следующее распределение случайной величины X – числа появления белых шаров (см. пример 1, §40 данного справочника):
| Число белых шаров, xi | 0 | 1 | 2 | 3 | 4 | 5 |
| pi | (mathrm{C_5^0q^5}) | (mathrm{C_5^1pq^4}) | (mathrm{C_5^2p^2q^3}) | (mathrm{C_5^3p^3q^2}) | (mathrm{C_5^4p^4q}) | (mathrm{C_5^5p^5}) |
| 0,0074 | 0,0618 | 0,2060 | 0,3433 | 0,2861 | 0,0954 |
Найдём математическое ожидание для данного распределения:
M(X) = 0 · 0,0074 + 1 · 0,0618 + … + 5 · 0,0954 = 3,125
п.3. Дисперсия
Дисперсия дискретной случайной величины X = {xi} – это математическое ожидание квадрата отклонения случайной величины от её математического ожидания: $$ mathrm{ D(X)=M(X-M(X))^2 } $$ На практике дисперсия рассчитывается по формуле: $$ mathrm{ D(X)=M(X)^2-M^2(X)=sum_{i=1}^n x_i^2p_i-M^2(X) } $$
Свойства дисперсии
1) Размерность дисперсии равна квадрату размерности случайной величины.
2) Дисперсия может быть любым неотрицательным действительным числом.
3) Дисперсия постоянной величины равна нулю:
D(C) = 0
4) Дисперсия суммы независимых случайных величин равна сумме дисперсий:
D(X + Y) = D(X) + D(Y)
5) Постоянный множитель можно вынести за знак дисперсии:
D(CX) = C2 · D(X)
Например:
Продолжим исследование и найдём дисперсию для распределения случайной величины X – числа появления белых шаров. Составим расчётную таблицу:
pi
0,0074
0,0618
0,2060
0,3433
0,2861
0,0954
1
xip1
0
0,0618
0,4120
1,0300
1,1444
0,4768
3,125
(mathrm{x_i^2})
0
1
4
9
16
25
–
(mathrm{x_i^2p_i})
0
0,0618
0,8240
3,0899
4,5776
2,3842
10,9375
Получаем: D(X) = 10,9375 – 3,1252 ≈ 1,1719.
п.4. Среднее квадратичное отклонение
Среднее квадратичное отклонение (СКО) дискретной случайной величины X = {xi} – это корень квадратный от дисперсии: $$ mathrm{ sigma(X)=sqrt{D(X)} } $$ СКО характеризует степень отклонения случайной величины от среднего значения.
Свойства СКО
1) Размерность СКО равна размерности случайной величины.
2) СКО может быть любым неотрицательным действительным числом.
3) СКО постоянной величины равно нулю:
σ(C) = 0
4) Постоянный множитель можно вынести за знак СКО:
σ(CX) = C · σ(X)
п.5. Правило трёх сигм
Большое количество случайных величин, измеряемых в экспериментах (например, в школьных лабораторных работах), имеет так называемое нормальное распределение.
В частности, при больших n, биномиальное распределение можно с хорошей точностью описывать как нормальное с M(X) = np и (mathrm{sigma(X)=sqrt{npq}}).
График плотности нормального распределения p(x) похож на колокол, с максимумом, соответствующим M(X) = Xcp – среднему значению измеряемой величины.
Величина СКО σ(X) характеризует степень отклонения X от среднего значения M(X).
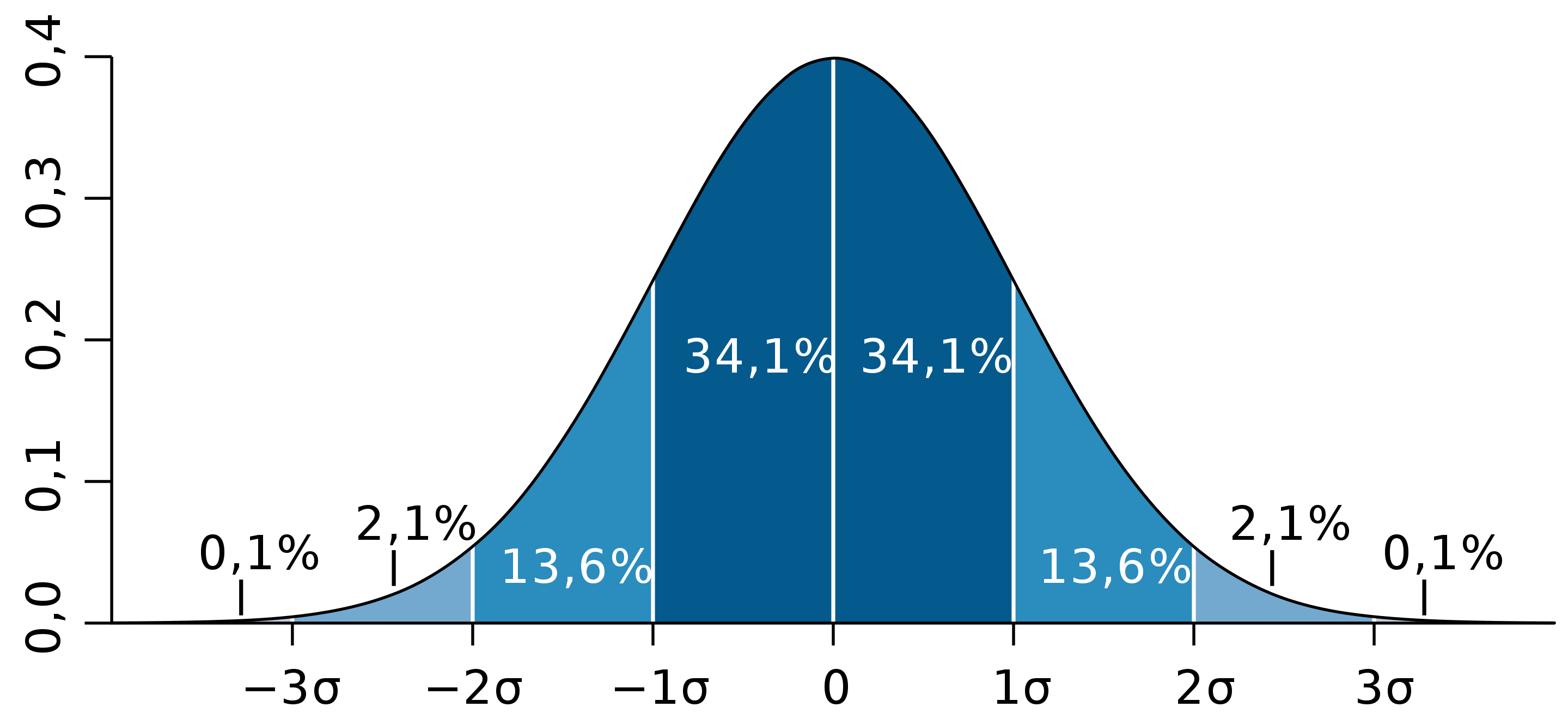
Если величина X имеет нормальное распределение, то в пределах
±σ лежит 68,26% значений, принимаемых этой величиной
±2σ лежит 95,44% значений, принимаемых этой величиной
±3σ лежит 99,72% значений, принимаемых этой величиной
Вероятность того, что нормально распределённая величина примет значение, отклоняющееся от среднего больше, чем на «три сигмы», равна 0,28%, т.е. пренебрежимо мала.
п.6. Примеры
Пример 1. Найдите математическое ожидание, дисперсию и СКО при бросании кубика.
Закон распределения величины X – очки на верхней грани при бросании кубика и расчётная таблица:
pi
1/6
1/6
1/6
1/6
1/6
1/6
1
xip1
1/6
1/3
1/2
2/3
5/6
1
3,5
(mathrm{x_i^2})
1
4
9
16
25
36
–
(mathrm{x_i^2p_i})
(mathrm{frac16})
(mathrm{frac23})
(mathrm{1frac12})
(mathrm{2frac23})
(mathrm{4frac16})
6
(mathrm{15frac16})
Получаем: begin{gather*} mathrm{ M(X)=sum_{i=1}^6 x_ip_i=3,5 }\ mathrm{ D(X)=sum_{i=1}^6 x_i^2p_i-M^2(X)=15frac16-3,5^3=2frac{11}{12} }\ mathrm{ sigma(X)=sqrt{D(X)}=sqrt{2frac{11}{12}}approx 1,7 } end{gather*} Ответ: (mathrm{M(X)=3,5; D(X)=2frac{11}{12}; sigma(X)approx 1,7}).
Пример 2*. Найти математическое ожидание, дисперсию и СКО суммы очков при бросании двух кубиков.
Используем свойства мат.ожиданий и дисперсий.
Пусть X – очки на первом кубике, Y – на втором.
Параметры распределения для каждого из кубиков рассчитаны в примере 1.
(mathrm{M(X)=M(Y)=3,5, D(X)=D(Y)=2frac{11}{12}}).
Для суммы очков получаем:
(mathrm{M(X+Y)=M(X)+M(Y)=3,5+3,5=7})
(mathrm{D(X+Y)=D(X)+D(Y)=2frac{11}{12}+2frac{11}{12}=5frac56})
(mathrm{sigma(X+Y)=sqrt{D(X+Y)}=sqrt{5frac56}approx 2,4})
Ответ: (mathrm{M(X+Y)=7; D(X+Y)=5frac56; sigma(X+Y)approx 2,4}).
Пример 3*. Докажите, что в опытах по схеме Бернулли математическое ожидание M(X)=np, а дисперсия D(X)=npq.
Проведем один опыт. В нём может быть только два исхода: «успех» и «неудача».
Составим расчётную таблицу:
(mathrm{x_i^2p_i})
0
p
p
Мат.ожидание первого опыта (mathrm{M(X)=sum x_ip_i=p}).
Общее число успехов при n опытах складывается из числа успехов при каждом опыте, т.е. (mathrm{X=X_1+X_2+…+X_n}). Все опыты между собой независимы.
По свойству мат.ожидания суммы независимых событий: begin{gather*} mathrm{ M(X)=M(X_1+X_2+…+X_n)=M(X_1)+M(X_2)+…+M(X_n)= }\ mathrm{=underbrace{p+p+…+p}_{n text{раз}}=np } end{gather*} Дисперсия первого опыта (mathrm{D(X)=sum x_i^2p_i-M(X)=p-p^2=p(1-p)=pq})
По свойству дисперсии суммы независимых событий: begin{gather*} mathrm{ D(X)=D(X_1+X_2+…+X_n)=D(X_1)+D(X_2)+…+D(X_n)= }\ mathrm{=underbrace{pq+pq+…+pq}_{n text{раз}}=npq } end{gather*} Что и требовалось доказать.
Пример 4. 100 канцелярских кнопок высыпали на стул. Вероятность, что кнопка упала острием вверх, равна 0,4. Найдите среднее количество, дисперсию и СКО для числа кнопок, упавших острием вверх. Найдите интервал оценки для количества этих кнопок по правилу «трёх сигм».
По условию n = 100, p = 0,4.
Для каждой кнопки может быть два исхода: упасть острием вверх или вниз.
Таким образом, это испытание Бернулли с биномиальным распределением случайной величины. begin{gather*} mathrm{ M(X)=np=100cdot 0,4=40 }\ mathrm{D(X)=npq=100cdot 0,4cdot 0,6=24 }\ mathrm{sigma(X)=sqrt{D(X)}=sqrt{24}approx 4,9} end{gather*} Интервал оценки «три сигмы»: begin{gather*} mathrm{ M(X)-3sigma(X)lt Xlt M(X)+3sigma(X) }\ mathrm{40-3cdot 4,9lt Xlt 40+3cdot 4,9 }\ mathrm{25,3lt Xlt 54,7}\ mathrm{26leq Xleq 54} end{gather*} Скорее всего (99,7%), от 26 до 54 кнопок будут острием вверх.
Ответ: (mathrm{M(X)=40; D(X)=24; sigma(X)approx 4,9; 26leq Xleq 54})
Пример 5*. В тесте 10 задач с 4 вариантами ответов. Ответы выбираются наугад. Постройте распределение величины X = «количество угаданных ответов», найдите числовые характеристики этого распределения.
Найдите интервал оценки для количества угаданных ответов по правилу «трёх сигм».
Какова вероятность угадать хотя бы 1 ответ? Хотя бы 5 ответов? Угадать все 10 ответов?
По условию: (mathrm{n=10, p=frac14, q=frac34}).
Для каждого ответа может быть два исхода: «угадал»/ «не угадал».
Таким образом, это испытание Бернулли с биномиальным распределением случайной величины. $$ mathrm{ P_{10}(k)=C_{10}^kp^kq^{10-k}=C_{10}^kfrac{3^{10-k}}{4^{10}}=left(frac34right)^{10}frac{C_{10}^k}{3^k} } $$ Строим расчётную таблицу. Для (mathrm{C_{10}^k}) используем рекуррентную формулу (см. §36 данного справочника): $$ mathrm{ C_{n}^k=frac{n-k+1}{k}C_n^{k-1} } $$
| (mathrm{x_i=k}) | (mathrm{C_k}) | (mathrm{3^k}) | (mathrm{p_i(x_i)}) | (mathrm{x_icdot p_i}) | (mathrm{x_i^2}) | (mathrm{x_i^2cdot p_i}) |
| 0 | 1 | 1 | 0,0563135 | 0,0000000 | 0 | 0,0000000 |
| 1 | 10 | 3 | 0,1877117 | 0,1877117 | 1 | 0,1877117 |
| 2 | 45 | 9 | 0,2815676 | 0,5631351 | 4 | 1,1262703 |
| 3 | 120 | 27 | 0,2502823 | 0,7508469 | 9 | 2,2525406 |
| 4 | 210 | 81 | 0,1459980 | 0,5839920 | 16 | 2,3359680 |
| 5 | 252 | 243 | 0,0583992 | 0,2919960 | 25 | 1,4599800 |
| 6 | 210 | 729 | 0,0162220 | 0,0973320 | 36 | 0,5839920 |
| 7 | 120 | 2187 | 0,0030899 | 0,0216293 | 49 | 0,1514053 |
| 8 | 45 | 6561 | 0,0003862 | 0,0030899 | 64 | 0,0247192 |
| 9 | 10 | 19683 | 0,0000286 | 0,0002575 | 81 | 0,0023174 |
| 10 | 1 | 59049 | 0,0000010 | 0,0000095 | 100 | 0,0000954 |
| Σ | 1 | 2,5 | 8,125 |
Получаем: begin{gather*} mathrm{ M(X)=sum_{i=0}^{10} x_ip_i=2,5 }\ mathrm{ D(X)=sum_{i=0}^{10} x_i^2p_i-M^2(X)=8,125=2,5^2=1,875 }\ mathrm{ sigma(X)=sqrt{D(X)}=sqrt{1,875}approx 1,37 } end{gather*} 
Интервал оценки «три сигмы»: begin{gather*} mathrm{ M(X)-3sigma(X) lt Xlt M(X)+3sigma(X) }\ mathrm{ 2,5-3cdot 1,37lt X lt 2,5+3cdot 1,37 }\ mathrm{ -1,61lt Xlt 6,61 }\ mathrm{ 0leq Xleq 6 } end{gather*} Скорее всего (по расчетам – 99,65%), вы угадаете от 0 до 6 ответов.
Вероятность угадать хотя бы один ответ: begin{gather*} mathrm{ P(Xgeq 1)=1-p_0approx 1-0,0563=0,9437 }end{gather*} Очень хорошие шансы – 94,37%.
Вероятность угадать хотя бы 5 ответов: begin{gather*} mathrm{ P(Xgeq 5)=1-left(sum_{i=0}^{4}{p_i} right)approx 1-(0,0563+0,1877+…+0,1460)=0,0781 }end{gather*} Шансов мало – 7,81%. Т.е. «средний балл» при сдаче тестов мало достижим методом научного тыка.
Вероятность угадать все 10 ответов: p10≈ 0,000001. Шанс – один из миллиона.
Математическое ожидание, дисперсия, среднее квадратичное отклонение
Эти величины определяют некоторое
среднее значение, вокруг которого
группируются значения случайной
величины, и степень их разбросанности
вокруг этого среднего значения.
Математическое ожидание Mдискретной случайной величины — это
среднее значение случайной величины,
равное сумме произведений всех возможных
значений случайной величины на их
вероятности.
![]()
Свойства математического ожидания:
-
Математическое ожидание постоянной
величины равно самой постоянной . -
Постоянный множитель можно выносить
за знак математического ожидания . -
Математическое ожидание произведения
двух независимых случайных величин
равно произведению их математических
ожиданий . -
Математическое ожидание суммы двух
случайных величин равно сумме
математических ожиданий слагаемых
Для описания многих практически важных
свойств случайной величины необходимо
знание не только ее математического
ожидания, но и отклонения возможных ее
значений от среднего значения.
Дисперсия случайной величины— мера разброса случайной величины,
равная математическому ожиданию квадрата
отклонения случайной величины от ее
математического ожидания.
![]() .
.
Принимая во внимание свойства
математического ожидания, легко показать
что
![]()
Казалось бы естественным рассматривать
не квадрат отклонения случайной величины
от ее математического ожидания, а просто
отклонение. Однако математическое
ожидание этого отклонения равно нулю.
Это объясняется тем, что одни возможные
отклонения положительны, другие
отрицательны, и в результате их взаимного
погашения получается ноль. Можно было
бы принять за меру рассеяния математическое
ожидание модуля отклонения случайной
величины от ее математического ожидания,
но как правило, действия связанные с
абсолютными величинами, приводят к
громоздким вычислениям.
Свойства дисперсии:
-
Дисперсия постоянной равна нулю.
-
Постоянный множитель можно выносить
за знак дисперсии, возводя его в квадрат. -
Если x и y независимые случайные величины
, то дисперсия суммы этих величин равна
сумме их дисперсий.
Средним квадратическим отклонением
случайной величины(иногда применяется
термин «стандартное отклонение случайной
величины») называется число равное![]() .
.
Среднее квадратическое отклонение,
является, как и дисперсия, мерой рассеяния
распределения, но измеряется, в отличие
от дисперсии, в тех же единицах, которые
используют для измерения значений
случайной величины.
Решение задач:
1)Дана случайная величина Х:
-
xi
-3
-2
0
1
2
pi
0,1
0,2
0,05
0,3
0,35
Найти М(х), D(X).
Решение:
![]() .
.
![]() =9
=9![]() =2,31.
=2,31.
![]() .
.
2) Известно, что М(Х)=5, М(Y)=2.
Найти математическое ожидание случайной
величиныZ=6X-2Y+9-XY.
Решение:М(Z)=6М(Х)-2М(Y)+9-M(X)M(Y)=30-4+9-10=25.
Пример:Известно, чтоD(Х)=5,D(Y)=2. Найти
математическое ожидание случайной
величиныZ=6X-2Y+9.
Решение:D(Z)=62D(Х)-22D(Y)+0=180-8=172.
Тема 7. Непрерывные случайные величины
Задача 14
Случайная
величина, значения которой заполняют
некоторый промежуток, называется
непрерывной.
Плотностью распределениявероятностей непрерывной случайной
величины Х называется функцияf(x)– первая производная от функции
распределенияF(x).
![]()
Плотность
распределения также называют
дифференциальной
функцией.
Для описания дискретной случайной
величины плотность распределения
неприемлема.
Зная плотность распределения, можно
вычислить вероятность того, что некоторая
случайная величина Х примет значение,
принадлежащее заданному интервалу.
Вероятность того, что непрерывная
случайная величина Х примет значение,
принадлежащее интервалу (a,
b), равна определенному
интегралу от плотности распределения,
взятому в пределах от a
до b.
![]()
Функция распределения может быть легко
найдена, если известна плотность
распределения, по формуле:
![]()
Свойства плотности распределения.
1) Плотность распределения – неотрицательная
функция.
![]()
2) Несобственный интеграл
от плотности распределения в пределах
от -доравен единице.
![]()
Решение задач.
1.Случайная величина подчинена
закону распределения с плотностью:

Требуется найти коэффициент а,
определить вероятность того, что
случайная величина попадет в интервал
от 0 до![]() .
.
Решение:
Для нахождения коэффициента авоспользуемся свойством![]() .
.
![]()
![]()
![]()
2 .Задана непрерывная случайная
величинахсвоей функцией распределенияf(x).
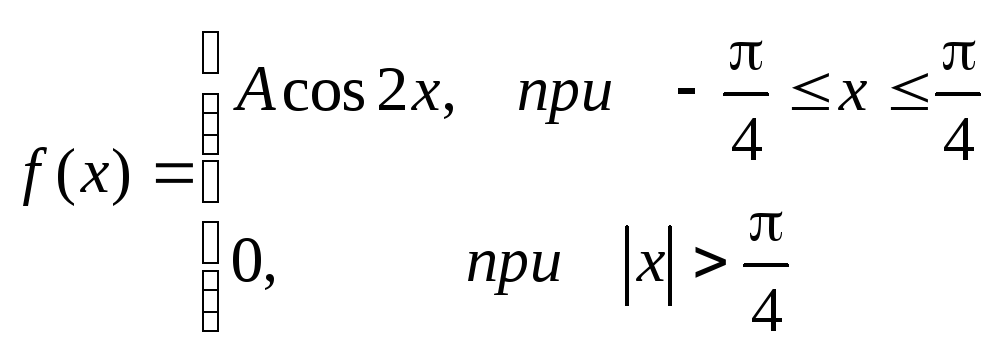
Требуется определить
коэффициент А, найти функцию распределения,
определить вероятность того, что
случайная величинахпопадет в
интервал![]() .
.
Решение:
Найдем коэффициент А.
![]()
Найдем функцию распределения:
1) На участке
![]() :
:![]()
2) На участке
![]()
![]()
3) На участке
![]()
![]()
Итого:


Найдем вероятность попадания случайной
величины в интервал
![]() .
.
![]()
Ту же самую вероятность можно искать
и другим способом:
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #