Indeed, there is an elegant way to compute this.
The process of finding the language accepted by an automaton $A = (Q,Sigma, delta, q_0, F)$ involves solving a system of equations over the monoid $(Sigma, circ, epsilon)$ with $epsilon$ denoting the empty word of the alphabet.
Denote as $Xi_i$ the language recognized by the automaton $(Q, Sigma, delta, q_i, F)$ and $Q= left{q_0,..,q_n right}$.
That is, create for each state of the initial automaton a new automaton with an initial state $q_i$, for $i=0,1,..,n$. Now denote $L_{ij}$ the language consisting of all the letters on the diagram of $A$ that start from $q_i$ and end at $q_j$. So from there there is the system
$$Xi_i = bigcup L_{ij} Xi_j cup Mi$$
where $M_i = emptyset$ if state $i$ is not final, ${epsilon}$ otherwise.
So to find the language of the automaton $A$ we got to solve the above system of equations and find $Xi_0$ under the operations defined by the monoid.
To solve this system we can use the following lemma:
Lemma: Let $L.M subset Sigma^*$ languages. The smallest language satisfying the equation
$$Z = LZ cup M$$ is $L^* M$.
For example consider the automaton:
$A = (left{q_0,q_1,q_2right},left{a,b right},delta, q_0,left{q_2 right})$ with the state diagram of $delta$ as follows

The system of equations is
$$begin{cases}
Xi_0 = a Xi_0 cup b Xi_1
\ Xi_1 = bXi_0 cup a Xi_2
\ Xi_2 = (a cup b) Xi_0 cup left{epsilon right}
end{cases} $$
With substitution we obtain
$$begin{cases}
Xi_0 = a Xi_0 cup b Xi_1
\ Xi_1 = b Xi_0 cup a ((a cup b) Xi_0 cup left{epsilon right})
end{cases} $$
$$begin{cases}
Xi_0 = a Xi_0 cup b Xi_1
\ Xi_1 = b cup a ((a cup b)) Xi_0 cup a)
end{cases} $$
Substituting to the first equation we get
$$
Xi_0 = a Xi_0 cup b ((b cup a ((a cup b)) Xi_0 cup a)
$$
$$
Xi_0 = a cup (b^2 cup b a^2 cup b a b) Xi_0 cup ba
$$
Finally, applying our lemma
$$
Xi_0 = (a cup b^2 cup b a^2 cup b a b)^* ba
$$
Thus the language accepted by the automaton is
$$L(A) = (a cup b^2 cup b a^2 cup b a b)^* ba $$ as one can validate easily.
-

-
May 22 2006, 00:25
- IT
- История
- Наука
- Cancel
Седьмой семинар
Тема: Регулярные языки и конечные автоматы (продолжение).
Для получения регулярного языка, допускаемого конечным автоматом, в общем случае
необходимо решить систему уравнений в полукольце языков (аналогично решалась задача поиска
кратчайших расстояний в графе): ![]() . Не трудно убедиться, что это идемпотентное полукольцо с итерацией, в
. Не трудно убедиться, что это идемпотентное полукольцо с итерацией, в
котором мы можем решать уравнение вида ![]() (см. выше). Чтобы получить систему
(см. выше). Чтобы получить систему
уравнений, необходимо построить матрицу переходов для графа конечного автомата.
Рассмотрим пример, в котором регулярный язык без составления конечного
автомата и системы уравнений достаточно сложно. Рассмотрим алфавит ![]() , необходимо
, необходимо
получить регулярное выражения для языка, содержащего только чётное число единиц и чётное
число нулей. Попытки придумать регулярное выражение «в лоб» (например, ![]() ) дадут только частные случаи. Построим конечный автомат, допускающий цепочки
) дадут только частные случаи. Построим конечный автомат, допускающий цепочки
такого языка: очевидно, что возможно только четыре состояния: «чётное число нулей и
единиц», «чётное число нулей, нечётное — единиц», «нечётное число нулей и единиц» и
«нечётное число нулей и чётное число единиц», автомат со всеми возможными переходами
показан на рисунке 0.
|
|
![includegraphics[width=8cm]{fa_example3.eps}](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20362%20267'%3E%3C/svg%3E)
Каждому состоянию ![]() конечного автомата ставится в соответствие переменная
конечного автомата ставится в соответствие переменная![]() . Значение этой переменной суть есть регулярное выражение, задающее все слова,
. Значение этой переменной суть есть регулярное выражение, задающее все слова,
которые допускаются кончным автоматом, старующем из данного состояния. Очевидно, что язык,
допускаемый конечным автоматом получается сложением переменных всех стартовых состояний.
Каждой строке матрицы соответствует одно уравнение, при этом всем уравнениям,
соответствующим конечным состояниям автомата, необходимо прибавить ![]() .
.
В нашем примере получается следующая система уравнений, которая имеет решение:
Таким образом, регулярное выражение для языка, допускаемого автоматом, равно:
.
Детерминизация конечных автоматов
Выше уже было сказано о том, что при работе конечного автомата возможны «конфликтные
ситуации», когда существует два правила с одинаковой левой частью или![]() -переходы — в этом случае необходимо «знать заранее», какой путь следует
-переходы — в этом случае необходимо «знать заранее», какой путь следует
выбрать, чтобы цепочка всё же была прочитана. Такой подход очень неудобен в реализации,
поэтому воникает задача детерминизации конечного автомата, т.е. приведение его к
такому виду, что «конфликтныйе ситуации не возможны», а язык, допускаемый автоматом, не
изменяется.
Существует формальный алгоритм детерминизации автомата, который состоит из двух шагов:
- удаление
 -переходов;
-переходов; - собственно детерминизация.
Для данного автомата ![]() , автомат без
, автомат без ![]() -переходов будет
-переходов будет
иметь вид:
Рассмотрим пример: на рисунке 1 показаны автоматы с![]() -переходами и без — при этом они допускают один и тот же язык.
-переходами и без — при этом они допускают один и тот же язык.
|
|
![includegraphics[width=12cm]{fa_example4.eps}](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20541%20234'%3E%3C/svg%3E)
Детерминизация производится построением новых вершин и переходов. При этом в качестве
вершин графа автомата могут теперь выступать не отдельные состояния изначального
автомата, анаборы состояний, например ![]() .
.
В качестве нового исходного состояния принимается состояние ![]() . Далее для всех
. Далее для всех
букв алфавита стоятся новые вершины, в которые можно попасть из данной вершины. Для нашего
примера все новые состояния и переходы будут выглядеть так:
Новыми конечными вершинами являются все вершины, содержащие в себе хоть одну из конечных
вершин исходного автомата: ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Новые вершины можно переименовать. Граф детерменизированного автомата показан на рисунке
2.
|
|
![includegraphics[width=10cm]{fa_example4d.eps}](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20451%20228'%3E%3C/svg%3E)
Существует теорема, согласно которой для каждого автомата может быть построен
эквивалентный (допускающий тот же язык) автомат. Это позволяет для любого регулярного
языка построить детерминизированный автомат.
Из этой теоремы есть интересное следствие — с помощью детерменизированного автомата
можно получать автоматы не досускающие заданную цепочку. Для этого необходимо в
детерминизированном автомате, допускающем данную цепочку, взять в качестве конечных вершин
дополнение относительно всех вершин: ![]() .
.
Рассмотрим пример — необходимо получить автомат (в алфавите ![]() ), не допускающий
), не допускающий
идущих подряд букв ![]() . На рисунке 3 показан исходный
. На рисунке 3 показан исходный
автомат, допускающий все слова, содержащие подряд ![]() , затем тот же автомат, но
, затем тот же автомат, но
детерминизированный. Третьим показан автомат, не досускающий цепочки, содержащие подряд ![]() . В данном случае две правые вершины в последнем автомате можно объединить как
. В данном случае две правые вершины в последнем автомате можно объединить как
неверные состояния, в том смысле, что попав туда, автомат заведомо не прочитает
заданную цепочку.
|
|
![includegraphics[width=10cm]{fa_example5.eps}](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20448%20447'%3E%3C/svg%3E)
Аннотация: В данной лекции рассматриваются два наиболее распространенных способа конечного задания формального языка: грамматики и автоматы. Рассматриваются конечные автоматы, соответствующие в иерархии Хомского праволинейным грамматикам, определяются понятия конечного автомата, недетерминированного конечного автомата и распознаваемого конечным автоматом языка. Приведены практические примеры и упражнения для закрепления материала
Два наиболее распространенных способа конечного задания
формального языка — это грамматики и автоматы.
Автоматами в данном контексте называют математические модели
некоторых вычислительных устройств.
В этой лекции рассматриваются конечные автоматы,
соответствующие в иерархии Хомского
праволинейным грамматикам.
Более сильные вычислительные модели
будут определены позже,
в лекциях
«10»
,
«14»
и
«15»
.
Термин «автоматный язык» закреплен за языками,
распознаваемыми именно конечными автоматами,
а не какими-либо более
широкими семействами автоматов
(например, автоматами с магазинной памятью или
линейно ограниченными автоматами).
В разделе 2.1 определяются понятия
конечного автомата
(для ясности такой автомат можно называть
недетерминированным конечным автоматом)
и
распознаваемого конечным автоматом языка.
В следующем разделе дается другое,
но эквивалентное первому определение
языка, распознаваемого конечным автоматом.
Оно не является необходимым для дальнейшего изложения,
но именно это определение поддается обобщению
на случаи автоматов других типов.
В разделе 2.3 доказывается, что
тот же класс автоматных языков можно получить, используя
лишь конечные автоматы специального вида
(они читают на каждом такте ровно один символ
и имеют ровно одно начальное состояние).
Во многих учебниках конечными автоматами
называют именно такие автоматы.
Целую серию классических результатов теории формальных языков
составляют теоремы о точном соответствии некоторых классов
грамматик некоторым классам автоматов.
Первая теорема из этой серии, утверждающая, что
праволинейные грамматики порождают в точности автоматные языки,
доказывается в разделе 2.4.
Другая серия результатов связана с возможностью
сузить некоторый класс грамматик, не изменив при этом
класс порождаемых ими языков.
Обычно в таком случае грамматики из меньшего класса
называются грамматиками в нормальной форме.
В разделе 2.5*
формулируется результат такого типа
для праволинейных грамматик.
Сама эта теорема не представляет большого интереса,
но аналогичные результаты,
доказываемые позже для контекстно-свободных грамматик,
используются во многих доказательствах и алгоритмах.
Не все конечные автоматы подходят для конструирования
распознающих устройств, пригодных для практических приложений,
так как в общем случае конечный автомат не дает точного
указания, как поступать на очередном шаге,
а разрешает продолжать вычислительный процесс несколькими способами.
Этого недостатка нет у детерминированных конечных автоматов
(частного случая недетерминированных конечных автоматов),
определенных в разделе 2.6.
В разделе 2.7 доказывается, что
каждый автоматный язык
задается некоторым детерминированным конечным автоматом.
2.1. Недетерминированные конечные автоматы
Определение 2.1.1. Конечный автомат
(finite automaton, finite-state machine) —
это пятерка 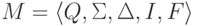 ,
,
где 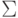 —
—
конечный входной алфавит
(или просто алфавит ) данного конечного автомата, 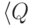 и
и  — конечные множества,
— конечные множества,
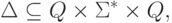
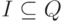 ,
, 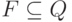 .
.
Элементы Q
называются состояниями
(state),
элементы I — начальными
(initial) состояниями,
элементы F — заключительными
или допускающими
(final, accepting) состояниями.
Если 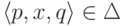 ,
,
то 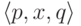
называется переходом
(transition) из p в q,
а слово x — меткой
(label) этого перехода.
Пример 2.1.2.
Пусть Q = {1,2}, 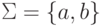 , I = {1}, F = {2},
, I = {1}, F = {2},
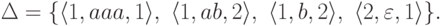
Тогда  —
—
конечный автомат.
Замечание 2.1.3.
Конечные автоматы можно изображать в виде диаграмм состояний
(state diagram) (иногда их называют диаграммами переходов
(transition diagram)).
На диаграмме каждое состояние обозначается кружком,
а переход — стрелкой.
Стрелка из p в q,
помеченная словом x,
показывает, что
является переходом данного конечного автомата.
Каждое начальное состояние распознается
по ведущей в него короткой стрелке.
Каждое допускающее состояние отмечается на диаграмме
двойным кружком.
Пример 2.1.4.
На диаграмме изображен конечный автомат из примера 2.1.2.
![objectwidth={5mm} objectheight={5mm} letobjectstyle=scriptstyle
xymatrix {
*=[o][F-]{1}
ar @`{+/l16mm/} [] ^{}
rloop{0,1} ^{aaa}
ar `ur_r{+/u7mm/}`r_dr{[0,2]}^{ab} "1,3"
ar "1,3" ^{b}
&
& *=[o][F=]{2}
ar `dl_l{+/d7mm/}`l_ul{[0,-2]}^{varepsilon} "1,1"
}](https://intuit.ru/sites/default/files/tex_cache/26d7eff928e8c48fd27971bb0fe90955.png)
Замечание 2.1.5.
Если в конечном автомате имеются
несколько переходов с общим началом и общим концом,
то такие переходы называются параллельными.
Иногда на диаграмме состояний конечного автомата
параллельные переходы изображают одной стрелкой.
При этом метки переходов перечисляют через запятую.
Пример 2.1.6.
На диаграмме снова изображен
конечный автомат из примера 2.1.2.
![objectwidth={5mm} objectheight={5mm} letobjectstyle=scriptstyle
xymatrix {
*=[o][F-]{1}
ar @`{+/l16mm/} [] ^{}
rloop{0,1} ^{aaa}
ar "1,3" <1mm> ^{ab,b}
&
& *=[o][F=]{2}
ar "1,1" <1mm> ^{varepsilon}
}](https://intuit.ru/sites/default/files/tex_cache/1bf41d4ad8a230143b77bbb63df0e14a.png)
Определение 2.1.7. Путь
(path) конечного автомата — это кортеж 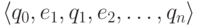 ,
,
где 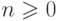
и 
для каждого i.
При этом q0 — начало пути qn — конец пути n — длина пути w1…wn — метка пути.
Замечание 2.1.8.
Для любого состояния 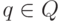
существует путь 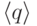 .
.
Его метка —  ,
,
начало и конец совпадают.
Определение 2.1.9.
Путь называется успешным
если его начало принадлежит I,
а конец принадлежит F.
Пример 2.1.10.
Рассмотрим конечный автомат из примера 2.1.2.
Путь 
является успешным.
Его метка — baaab.
Длина этого пути — 4.
Определение 2.1.11.
Слово w допускается
(is accepted, is recognized)
конечным автоматом M,
если оно является меткой некоторого успешного пути.
Определение 2.1.12.
Язык, распознаваемый
конечным автоматом M, —
это язык L(M), состоящий из меток всех успешных путей
(то есть из всех допускаемых данным автоматом слов).
Будем также говорить, что автомат M распознает
(recognizes, accepts)
язык L(M).
Замечание 2.1.13.
Если 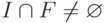 ,
,
то язык, распознаваемый конечным автоматом ,
содержит .
Пример 2.1.14.
Пусть ,
где Q = {1,2}, , I = {1}, F = {1,2},
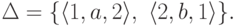
![objectwidth={5mm} objectheight={5mm} letobjectstyle=scriptstyle
xymatrix {
*=[o][F=]{1}
ar @`{+/l16mm/} [] ^{}
ar "1,2" <0.6mm> ^{a}
& *=[o][F=]{2}
ar "1,1" <0.6mm> ^{b}
}](https://intuit.ru/sites/default/files/tex_cache/bc5170483f2b94c51b54497cdb532412.png)
Тогда

Определение 2.1.15.
Два конечных автомата эквивалентны,
если они распознают один и тот же язык.
Определение 2.1.16.
Язык L называется автоматным
(finite-state language),
если существует конечный автомат, распознающий этот язык.
Замечание 2.1.17.
Обычно в учебниках используется более узкое определение
недетерминированного конечного автомата, но это не меняет
класса автоматных языков (см. лемму 2.3.3.).
Пример 2.1.18.
Рассмотрим однобуквенный алфавит 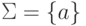 .
.
При любых фиксированных 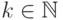
и 
язык 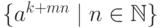
является автоматным.
Замечание 2.1.19.
Каждый конечный язык является автоматным.
Определение 2.1.20.
Состояние q достижимо
(reachable)
из состояния p,
если существует путь, началом которого является p,
а концом — q.
Лемма 2.1.21. Каждый автоматный язык распознается некоторым конечным автоматом,
в котором каждое состояние достижимо из некоторого начального состояния
и из каждого состояния достижимо хотя бы одно заключительное состояние.
Пример 2.1.22.
Рассмотрим конечный автомат ,
где Q = {1,2,3,4},  , I = {1,2,4}, F = {1,3,4},
, I = {1,2,4}, F = {1,3,4},
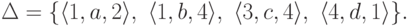
![objectwidth={5mm} objectheight={5mm} letobjectstyle=scriptstyle
xymatrix {
%
& *=[o][F=]{1}
ar @`{+/l16mm/} [] ^{}
ar "2,1" _{a}
ar "2,2" <0.6mm> ^{b}
& *=[o][F=]{3}
ar "2,2" ^{c}
\
*=[o][F-]{2}
ar @`{+/l16mm/} [] ^{}
& *=[o][F=]{4}
ar @`{+/l16mm/} [] ^{}
ar "1,2" <0.6mm> ^{d}
&
}](https://intuit.ru/sites/default/files/tex_cache/894fdb56825c1b103b19717e713daafc.png)
Удалим те состояния
(и содержащие их переходы),
которые не удовлетворяют требованиям леммы 2.1.21.
Получается эквивалентный конечный автомат 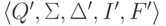 ,
,
где Q’ = {1,4}, I’ = {1,4}, F’ = {1,4},
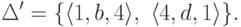
![objectwidth={5mm} objectheight={5mm} letobjectstyle=scriptstyle
xymatrix {
*=[o][F=]{1}
ar @`{+/l16mm/} [] ^{}
ar "2,1" <0.6mm> ^{b}
\
*=[o][F=]{4}
ar @`{+/l16mm/} [] ^{}
ar "1,1" <0.6mm> ^{d}
}](https://intuit.ru/sites/default/files/tex_cache/56000e2f1edb1abcf86855457cdc66ac.png)
Замечание 2.1.23
Естественным обобщением конечного автомата
является конечный преобразователь
(finite-state transducer),
позволяющий на каждом такте отправить несколько символов
в дополнительный «выходной» поток.
В некоторых книгах конечными автоматами
называют именно такие устройства (с выходным потоком).
В данном пособии конечные преобразователи
рассматриваться не будут.
Упражнение 2.1.24. Найти конечный автомат, распознающий язык 
Упражнение 2.1.25. Найти конечный автомат, распознающий язык 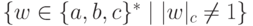
Упражнение 2.1.26. Найти конечный автомат, распознающий язык 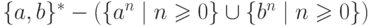
Упражнение 2.1.27. Найти конечный автомат, распознающий язык 
Упражнение 2.1.28. Найти конечный автомат, распознающий язык 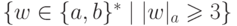
Упражнение 2.1.28. Найти конечный автомат, распознающий язык 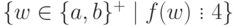 ,
,
где 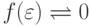 ,
, 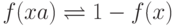
и 
для любого 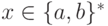
Детерминизация конечных автоматов
Для дальнейшего изучения свойств конечных автоматов и, в частности, для решения задачи синтеза важное значение имеет следующая теорема.
Теорема 7.7 (теорема о детерминизации). Для любого конечного автомата может быть построен эквивалентный ему детерминированный конечный автомат.
Для того чтобы доказать теорему, нужно, во-первых, описать алгоритм построения детерминированного конечного автомата по исходному; во-вторых, обосновать этот алгоритм, строго доказав, что он действительно дает конечный автомат, который является детерминированным и эквивалентным исходному. Здесь мы приведем только сам алгоритм построения детерминированного автомата.
Преобразование произвольного конечного автомата к эквивалентному детерминированному осуществляется в два этапа: сначала удаляются дуги с меткой , затем проводится собственно детерминизация.
1. Удаление λ-переходов (дуг с меткой ).
Чтобы перейти от исходного конечного автомата к эквивалентному конечному автомату
без λ-переходов, достаточно в исходном графе
проделать следующие преобразования.
а. Все состояния, кроме начального, в которые заходят только дуги с меткой , удаляются; тем самым определяется множество
конечного автомата
. Понятно, что
. При этом полагаем, что начальное состояние остается прежним.
б. Множество дуг конечного автомата и их меток (тем самым и функция переходов
) определяется так: для любых двух состояний
имеет место тогда и только тогда, когда
, а в графе
имеет место одно из двух: либо существует дуга из
в
, метка которой содержит символ
, либо существует такое состояние
, что
и
. При этом вершина
, вообще говоря, может и не принадлежать множеству
, т.е. она может и исчезнуть при переходе к автомату
(рис. 7.11). Если же
, то, естественно, в
сохранится дуга
и символ
будет одним из символов, принадлежащих метке этой дуги (рис. 7.12).
Таким образом, в сохраняются все дуги
, метки которых отличны от
и которые соединяют пару (вершин) состояний из множества
(не удаляемых согласно п. а). Кроме этого, для любой тройки состояний
(не обязательно различных!), такой, что
и существует путь ненулевой длины из
в
, метка которого равна
(т.е. путь по λ-переходам), а из
в
ведет дуга, метка которой содержит символ
входного алфавита, в
строится дуга из
в
, метка которой содержит символ
(см. рис. 7.11).
в. Множество заключительных состояний конечного автомата
содержит все состояния
, т.е. состояния конечного автомата
, не удаляемые согласно п. а, для которых имеет место
для некоторого
(т.е. либо состояние
само является заключительным состоянием конечного автомата
, либо из него ведет путь ненулевой длины по дугам с меткой
в одно из заключительных состояний конечного автомата
) (рис. 7.13).
2. Собственно детерминизация.
Пусть — конечный автомат без λ-переходов. Построим эквивалентный
детерминированный конечный автомат
.
Этот конечный автомат определяется таким образом, что его множество состояний есть множество всех подмножеств множества состояний конечного автомата . Это значит, что каждое отдельное состояние конечного автомата
определено как некоторое подмножество множества состояний конечного автомата
. При этом начальным состоянием нового конечного автомата (т.е.
) является одноэлементное подмножество, содержащее начальное состояние старого конечного автомата (т.е.
), а заключительными состояниями нового конечного автомата являются все такие подмножества
, которые содержат хотя бы одну заключительную вершину исходного конечного автомата
.
Впредь, допуская некоторую вольность речи, мы будем иногда называть состояния конечного автомата состояниями-множествами. Важно, однако, четко усвоить, что каждое такое состояние-множество есть отдельное состояние нового конечного автомата, но никак не множество его состояний. В то же время для исходного («старого») конечного автомата
это именно множество его состояний. Образно говоря, каждое подмножество состояний старого конечного автомата «свертывается» в одно состояние нового конечного автомата*.
*Формально следовало бы определить множество как множество, находящееся во взаимно однозначном соответствии с множеством
, но нам все-таки удобнее считать, что
совпадает с
, — ведь множеством состояний конечного автомата может быть любое непустое конечное множество.
Функция переходов нового конечного автомата определена так, что из состояния-множества по входному символу а конечный автомат
переходит в состояние-множество, представляющее собой объединение всех множеств состояний старого конечного автомата, в которые этот старый конечный автомат переходит по символу а из каждого состояния множества
. Таким образом, конечный автомат
является детерминированным по построению.
Приведенное выше словесное описание можно перевести в формулы следующим образом: строим конечный автомат так, что
, где
(7.8)
Обратим внимание на то, что среди состояний нового конечного автомата есть состояние , причем, согласно (7.8),
для любого входного символа
. Это значит, что, попав в такое состояние, конечный автомат
уже его не покинет. Вообще же любое состояние
конечного автомата, такое, что для любого входного символа
имеем
, называют поглощающим состоянием конечного автомата. Таким образом, состояние
детерминированного конечного автомата
является поглощающим. Полезно заметить также, что
тогда и только тогда, когда для каждого
(состояния старого конечного автомата из множества состояний
)
, т.е. в графе
из каждого такого состояния
не выходит ни одна дуга, помеченная символом
.
Можно доказать, что полученный по такому алгоритму конечный автомат эквивалентен исходному.
Пример 7.9. Детерминизируем конечный автомат, изображенный на рис. 7.14.
Эквивалентный конечный автомат без λ-переходов изображен на рис. 7.15. Заметим, что вершина исчезает, так как в нее заходят только «пустые» дуги.
Чтобы детерминизировать полученный автомат, совершенно не обязательно выписывать все его состояний, среди которых многие могут оказаться не достижимыми из начального состояния
. Чтобы получить достижимые из
состояния, и только их, воспользуемся так называемым методом вытягивания.
Этот метод в общем случае можно описать так.
В исходном конечном автомате (без пустых дуг) определяем все множества состояний, достижимых из начального, т.е. для каждого входного символа находим множество
. Каждое такое множество в новом автомате является состоянием, непосредственно достижимым из начального.
Для каждого из определенных состояний-множеств и каждого входного символа
находим множество
. Все полученные на этом шаге состояния будут состояниями нового (детерминированного) автомата, достижимыми из начальной вершины по пути длины 2. Описанную процедуру повторяем до тех пор, пока не перестанут появляться новые состояния-множества (включая пустое!). Можно показать, что при этом получаются все такие состояния конечного автомата
, которые достижимы из начального состояния
.
Для конечного автомата на рис. 7.15 имеем:
Так как новых состояний-множеств больше не появилось, процедура «вытягивания» на этом заканчивается, и мы получаем граф, изображенный на рис. 7.16.
Дополнение регулярного языка
Одним из важных теоретических следствий теоремы о детерминизации является следующая теорема.
Теорема 7.8. Дополнение регулярного языка есть регулярный язык.
Пусть — регулярный язык в алфавите
. Тогда дополнение языка
(как множества слов) есть язык
.
Согласно теореме 7.7, для регулярного языка может быть построен детерминированный конечный автомат
, допускающий
. Поскольку в детерминированном автомате из каждой вершины по каждому входному символу определен переход в точности в одну вершину, то, какова бы ни была цепочка
в алфавите
, для нее найдется единственный путь в
, начинающийся в начальном состоянии, на котором читается цепочка
. Ясно, что цепочка
допускается автоматом
, то есть
, тогда и только тогда, когда последнее состояние указанного пути является заключительным. Отсюда следует, что цепочка
тогда и только тогда, когда последнее состояние указанного пути не заключительное. Но нам как раз и нужен конечный автомат
, который допускает цепочку
тогда и только тогда, когда ее не допускает исходный конечный автомат
. Следовательно, превращая каждое заключительное состояние
в не заключительное и наоборот, получим детерминированный автомат, допускающий дополнение языка
.
Доказанная теорема позволяет строить конечный автомат, не допускающий определенное множество цепочек, следующим методом: строим сначала автомат, допускающий данное множество цепочек, затем детерминизируем его и переходим к автомату для дополнения так, как это указано в доказательстве теоремы 7.8.
Пример 7.10. а. Построим конечный автомат, допускающий все цепочки в алфавите , кроме цепочки 101.
Сначала построим конечный автомат, допускающий единственную цепочку 101. Этот автомат приведен на рис. 7.17.
Этот автомат квазидетерминированный, но не детерминированный, так как он не полностью определен. Проведем его детерминизацию и получим детерминированный эквивалентный конечный автомат, изображенный на рис. 7.18.
И наконец, переходя к дополнению (и переименовывая состояния), получим автомат, изображенный на рис. 7.19.
Обратим внимание, что в полученном автомате все вершины, кроме вершины , являются заключительными.
Заметим также, что переход к дополнению, о котором идет речь в доказательстве теоремы 7.8, может быть проведен только в детерминированном автомате. Если бы мы поменяли ролями заключительные и незаключительные вершины в автомате, изображенном на рис. 7.17, то получили бы автомат, допускающий язык , который не является — как нетрудно сообразить — множеством всех цепочек, отличных от цепочки 101.
Отметим также, что конечный автомат на рис. 7.19 допускает все цепочки, содержащие вхождение цепочки 101, но не совпадающие с самой этой цепочкой. Вот, например, путь, несущий цепочку 1011: .
б. Построим конечный автомат, допускающий все цепочки в алфавите , кроме тех, которые содержат вхождение цепочки 101. Рассмотрим язык
, каждая цепочка которого содержит вхождение цепочки 101. Его можно задать так:
Нам нужно построить автомат для дополнения языка .
Непосредственно по регулярному выражению в этом случае легко построить конечный автомат, допускающий язык (рис. 7.20).
Затем методом «вытягивания» проведем детерминизацию. Результат детерминизации представлен на рис. 7.21.
Для полного решения задачи осталось только на рис. 7.21 поменять ролями заключительные и не заключительные вершины (рис. 7.22).
в. Обсудим идею построения конечного автомата, допускающего те и только те цепочки в алфавите , которые не начинаются цепочкой 01 и не заканчиваются цепочкой 11 (т.е. не разрешаются цепочки вида
и цепочки вида
, каковы бы ни были цепочки
).
В этом случае дополнением языка, для которого нужно построить конечный автомат, является множество всех таких цепочек нулей и единиц, которые начинаются цепочкой 01 или заканчиваются цепочкой 11. Допускающий это множество цепочек автомат строится как автомат для объединения тем способом, который изложен при доказательстве теоремы Клини (см. теорему 7.6).
Из свойства замкнутости класса регулярных языков относительно дополнения (см. теорему 7.8) немедленно вытекает замкнутость этого класса относительно пересечения, теоретико-множественной и симметрической разности.
Следствие 7.3. Для любых двух регулярных языков и
справедливы следующие утверждения:
1) пересечение регулярно;
2) разность регулярна;
3) симметрическая разность регулярна.
Справедливость утверждений вытекает из тождеств:
Во-первых, полученные результаты позволяют утверждать, что класс регулярных языков относительно операций объединения, пересечения и дополнения является булевой алгеброй, в которой единицей служит универсальный язык, а нулем — пустой язык. Во-вторых, эти алгебраические свойства семейства регулярных языков позволяют решить важную проблему распознавания эквивалентности двух произвольных конечных автоматов.
Согласно определению 7.10, конечные автоматы эквивалентны, если допускаемые ими языки совпадают. Поэтому, чтобы убедиться в эквивалентности автоматов и
, достаточно доказать, что симметрическая разность языков
и
пуста. Для этого, в свою очередь, достаточно построить автомат, допускающий эту разность, и убедиться в том, что допускаемый им язык пуст. В общем случае проблему распознавания того, что язык конечного автомата пуст, называют проблемой пустоты для конечного автомата. Чтобы решить эту проблему, достаточно найти множество заключительных состояний автомата, достижимых из начального состояния. Так как конечный автомат — это ориентированный граф, то решить такую проблему можно, например, с помощью, поиска в ширину. Язык, допускаемый конечным автоматом, пуст тогда и только тогда, когда множество заключительных состояний, достижимых из начального состояния, пусто. Практически эквивалентность конечных автоматов предпочтительнее распознавать, используя алгоритм минимизации, но сейчас нам важно подчеркнуть, что принципиальная возможность решить проблему эквивалентности вытекает из теоремы 7.7 и ее алгебраических следствий.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.