В этом учебном пособии вы узнаете, как использовать функцию REGEXP_INSTR Oracle/PLSQL с синтаксисом и примерами.
Описание
Функция Oracle/PLSQL REGEXP_INSTR является расширением функции INSTR. Она возвращает местоположение шаблона регулярного выражения в строке. Эта функция, представленная в Oracle 10g, позволит вам найти подстроку в строке, используя сопоставление шаблонов регулярных выражений.
Синтаксис
Синтаксис функции Oracle/PLSQL REGEXP_INSTR:
REGEXP_INSTR( string, pattern [, start_position [, nth_appearance [, return_option [, match_parameter [, sub_expression ] ] ] ] ] )
Параметры или аргументы
string
Строка для поиска. Строкой могут быть CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB или NCLOB.
pattern
Шаблон. Регулярное выражение для сопоставления. Это может быть комбинацией следующих значений:
| Значение | Описание |
|---|---|
| ^ | Соответствует началу строки. При использовании match_parameter с m, соответствует началу строки в любом месте в пределах выражения. |
| $ | Соответствует концу строки. При использовании match_parameter с m, соответствует концу строки в любом месте в пределах выражения. |
| * | Соответствует нолю или более вхождений. |
| + | Соответствует одному или более вхождений. |
| ? | Соответствует нолю или одному вхождению. |
| . | Соответствует любому символу, кроме NULL. |
| | | Используется как «OR», чтобы указать более одной альтернативы. |
| [ ] | Используется для указания списка совпадений, где вы пытаетесь соответствовать любому из символов в списке. |
| [^ ] | Используется для указания списка nonmatching, где вы пытаетесь соответствовать любому символу, за исключением тех кто в списке. |
| ( ) | Используется для групповых выражений в качестве подвыражений. |
| {m} | Соответствует m раз. |
| {m,} | Соответствие как минимум m раз. |
| {m,n} | Соответствие как минимум m раз, но не более n раз. |
| n | n представляет собой число от 1 до 9. Соответствует n-му подвыражению находящемуся в ( ) перед n. |
| [..] | Соответствует одному сопоставлению элемента, который может быть более одного символа. |
| [::] | Соответствует классу символов. |
| [==] | Соответствует классу эквивалентности |
| d | Соответствует цифровому символу. |
| D | Соответствует не цифровому символу. |
| w | Соответствует текстовому символу. |
| W | Соответствует не текстовому символу. |
| s | Соответствует символу пробел. |
| S | Соответствует не символу пробел. |
| A | Соответствует началу строки или соответствует концу строки перед символом новой строки. |
| Z | Соответствует концу строки. |
| *? | Соответствует предыдущему шаблону ноль или более вхождений. |
| +? | Соответствует предыдущему шаблону один или более вхождений. |
| ?? | Соответствует предыдущему шаблону ноль или одному вхождению. |
| {n}? | Соответствует предыдущему шаблону n раз. |
| {n,}? | Соответствует предыдущему шаблону, по меньшей мере n раз. |
| {n,m}? | Соответствует предыдущему шаблону, по меньшей мере n раз, но не более m раз. |
start_position
Необязательный. Это позиция в строке, откуда начнется поиск. Если этот параметр опущен, по умолчанию он равен 1, который является первой позицией в строке.
nth_appearance
Необязательный. Это n-ое вхождение шаблона в строке. Если этот параметр опущен, по умолчанию он равен 1, который является первым вхождением шаблона в строке.
return_option
Необязательный. Если return_option обозначен 0, то возвращается позиция первого символа входящего в шаблон. Если return_option обозначен 1, то возвращается позиция после символа входящего в шаблон. Если этот параметр опущен, он по умолчанию равен 0.
match_parameter
Необязательный. Это позволяет изменять поведение соответствия для условия REGEXP_INSTR. Это может быть комбинацией следующих значений:
| Значение | Описание |
|---|---|
| ‘c’ | Выполняет чувствительное к регистру согласование. |
| ‘i’ | Выполняет не чувствительное к регистру согласование. |
| ‘n’ | Позволяет период символа (.) для соответствия символа новой строки. По умолчанию, период метасимволы. |
| ‘m’ | Выражение допускает, что есть несколько строк, где ^ это начало строки, а $ это конец строки, независимо от позиции этих символов в выражении. По умолчанию предполагается, что выражение в одной строке. |
| ‘x’ | Игнорируются символы пробелов. По умолчанию, символы пробелов совпадают, как и любой другой символ. |
subexpression
Необязательный. Используется, когда шаблон имеет подвыражения, и вы хотите указать, какое подвыражение в шаблоне является целью. Это целочисленное значение от 0 до 9, указывающее, что подвыражение соответствует шаблону.
Функция REGEXP_INSTR возвращает числовое значение.
Если функция REGEXP_INSTR не обнаруживает никакого соответствия шаблону, она вернет 0.
Примечание
Если в параметре match_parameter имеются конфликтующие значения, функция REGEXP_INSTR будет использовать последнее значение.
См. Также функцию INSTR.
Применение
Функцию REGEXP_INSTR можно использовать в следующих версиях Oracle / PLSQL:
- Oracle 12c, Oracle 11g, Oracle 10g
Пример совпадения по единичному символу
Начнем с рассмотрения простейшего случая. Давайте найдем позицию первого символа ‘o’ в строке.
Например:
|
SELECT REGEXP_INSTR (‘Oracle Cloud Infrastructure’, ‘o’) FROM dual; |
Этот пример вернет 10, потому что он выполняет поиск по регистру ‘o’ с учетом регистра. Поэтому он пропускает символы ‘O’ и находит первую ‘o’ в 10-й позиции.
Если мы захотим включить в результат как маленькую ‘o’, так и большую ‘O’ и выполнить поиск без учета регистра, то изменим наш запрос следующим образом:
|
SELECT REGEXP_INSTR (‘Oracle Cloud Infrastructure’, ‘o’, 1, 1, 0, ‘i’) FROM dual; |
Теперь, поскольку мы предоставили start_position = 1, nth_appearance = 1, return_option = 0 и match_parameter = ‘i’, запрос вернет 1 в качестве результата. На этот раз функция будет искать значения ‘o’ и ‘O’ и вернет первое вхождение.
Если бы мы захотели найти первое вхождение символа ‘o’ в столбце, то мы могли бы попробовать что-то вроде этого (без учета регистра):
|
SELECT REGEXP_INSTR (last_name, ‘o’, 1, 1, 0, ‘i’) AS First_Occurrence FROM contacts; |
Это вернет первое вхождение значений ‘o’ или ‘O’ в поле last_name из таблицы contacts.
Пример совпадения нескольких символов
Рассмотрим, как мы будем использовать функцию REGEXP_INSTR для соответствия многосимвольной схеме.
Например:
|
SELECT REGEXP_INSTR (‘The example shows how to use the REGEXP_INSTR function’, ‘ow’, 1, 1, 0, ‘i’) FROM dual; —Результат: 15 |
В этом примере будет возвращено первое вхождение ‘ow’ в строке. Оно будет соответствовать ‘ow’ в слове shows.
Мы могли бы изменить начальную позицию поиска, чтобы выполнить поиск, начиная с середины строки.
Например:
|
SELECT REGEXP_INSTR (‘The example shows how to use the REGEXP_INSTR function’, ‘ow’, 16, 1, 0, ‘i’) FROM dual; —Результат: 20 |
В этом примере поиск шаблона ‘ow’ в строке начнется с позиции 16. В этом случае поиска шаблона он пропустит первые 15 символов строки.
Рассмотрим, как мы будем использовать функцию REGEXP_INSTR со столбцом таблицы и искать несколько символов.
Например:
|
SELECT REGEXP_INSTR (other_number, ‘the’, 1, 1, 0, ‘i’) FROM contacts; |
В этом примере мы будем искать шаблон в поле other_number в таблице contacts.
Пример сопоставления несколько альтернатив.
Следующий пример, который мы рассмотрим, включает использование | шаблон. | шаблон используется как «ИЛИ», чтобы указать несколько альтернатив.
Например:
|
SELECT REGEXP_INSTR (‘AeroSmith’, ‘a|e|i|o|u’) FROM dual; —Результат: 2 |
Этот пример вернет 2, потому что он ищет первую гласную (a, e, i, o или u) в строке. Поскольку мы не указали значение match_parameter, функция REGEXP_INSTR выполнит поиск с учетом регистра, что означает, что символ ‘A’ в ‘AeroSmith’ не будет сопоставлен.
Мы могли бы изменить наш запрос, чтобы выполнить поиск без учета регистра следующим образом:
|
SELECT REGEXP_INSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 1, 0, ‘i’) FROM dual; —Результат: 1 |
Теперь, поскольку мы предоставили match_parameter = ‘i’, запрос вернет в качестве результата 1. На этот раз ‘A’ в ‘AeroSmith’ будет сопоставляться.
Рассмотрим, как вы будете использовать эту функцию со столбцом.
Итак, допустим, у нас есть таблица contact со следующими данными:
| contact_id | last_name |
|---|---|
| 1000 | AeroSmith |
| 2000 | Joy |
| 3000 | Scorpions |
Теперь давайте запустим следующий запрос:
|
SELECT contact_id, last_name, REGEXP_INSTR (last_name, ‘a|e|i|o|u’, 1, 1, 0, ‘i’) AS first_occurrence FROM contacts; |
Результаты, которые будут возвращены запросом:
| contact_id | last_name | first_occurrence |
|---|---|---|
| 1000 | AeroSmith | 1 |
| 2000 | Joy | 2 |
| 3000 | Scorpions | 3 |
Пример совпадений на основе параметра nth_occurrence
Следующий пример, который мы рассмотрим, включает параметр nth_occurrence. Параметр nth_occurrence позволяет вам выбрать, в каком месте шаблона вы хотите вернуть позицию.
Первое вхождение
Давайте посмотрим, как найти первое вхождение шаблона в строку.
Например:
|
SELECT REGEXP_INSTR (‘Regular expression’, ‘a|e|i|o|u’, 1, 1, 0, ‘i’) FROM dual; —Результат: 2 |
Этот пример вернет 2, потому что он ищет первое вхождение гласного (a, e, i, o или u) в строке.
Второе вхождение
Затем мы будем искать второе вхождение шаблона в строке.
Например:
|
SELECT REGEXP_INSTR (‘Regular expression’, ‘a|e|i|o|u’, 1, 2, 0, ‘i’) FROM dual; —Результат: 4 |
Этот пример вернет 4, потому что он ищет второе вхождение гласного (a, e, i, o или u) в строке.
Третье вхождение
Например:
|
SELECT REGEXP_INSTR (‘Regular expression’, ‘a|e|i|o|u’, 1, 3, 0, ‘i’) FROM dual; —Результат: 6 |
Этот пример вернет 6, потому что он ищет третье вхождение гласного (a, e, i, o или u) в строке.
Пример параметра return_option
Наконец, давайте посмотрим, как параметр return_option влияет на наши результаты.
Например:
|
SELECT REGEXP_INSTR (‘Regular expression’, ‘exp’, 1, 1, 0, ‘i’) FROM dual; —Результат: 9 |
В этом базовом примере мы ищем шаблон в строке, и поиск не зависит от регистра. Мы указали параметр return_option = 0, что означает, что будет возвращена позиция первого символа шаблона.
Теперь давайте изменим параметр return_option на 1 и посмотрим, что произойдет.
Например:
|
SELECT REGEXP_INSTR (‘Regular expression’, ‘exp’, 1, 1, 1, ‘i’) FROM dual; —Результат: 12 |
Параметр return_option = 1 сообщает функции REGEXP_INSTR, чтобы вернуть позицию символа, следующего за совпадающим шаблоном. В этом примере функция вернет 12.
Summary: in this tutorial, you will learn how to use the Oracle REGEXP_INSTR() function to search for a substring in a string using a regular expression pattern.
Introduction to Oracle REGEXP_INSTR() function
The REGEXP_INSTR() function enhances the functionality of the INSTR() function by allowing you to search for a substring in a string using a regular expression pattern.
The following illustrates the syntax of the REGEXP_INSTR() function:
Code language: SQL (Structured Query Language) (sql)
REGEXP_INSTR( string, pattern, position, occurrence, return_option, match_parameter )
The REGEXP_INSTR() function evaluates the string based on the pattern and returns an integer indicating the beginning or ending position of the matched substring, depending on the value of the return_option argument. If the function does not find any match, it will return 0.
Here is the detail of each argument:
string (mandatory)
Is the string to search.
pattern (mandatory)
Is a regular expression to be matched.
The maximum size of the pattern is 512 bytes. The function will convert the type of the pattern to the type of the string if the types of pattern and string are different.
position (optional)
Is a positive integer that determines start position in the string that the function begins the search.
The position defaults to 1, meaning that the function starts searching at the beginning of the string.
occurrence (optional)
Is a positive integer that determines for which occurrence of the pattern in the string the function should search. By default, the occurrence is 1, meaning that the function searches for the first occurrence of pattern.
return_option (optional)
The return_option can be 0 and 1. If return_option is 0, the function will return the position of the first character of the occurrence.
Otherwise, it returns the position of the character following the occurrence.
By default, return_option is 0.
match_parameter (optional)
Specify the default matching behavior of the function. The match_parameter accepts the values listed in the following table:
| Value | Description |
|---|---|
| ‘c’ | Performs case-sensitive matching. |
| ‘i’ | Performs case-insensitive matching. |
| ‘n’ | Allows the period (.), which is the match-any-character character, to match the newline character. If you skip this parameter, then the period (.) does not match the newline character. |
| ‘m’ | The function treats the string as multiple lines. The function interprets the caret (^) and the dollar sign ($) as the start and end, respectively, of any line anywhere in the string, rather than only at the start or end of the entire string. If you skip this parameter, then function treats the source string as a single line. |
| ‘x’ | Ignores whitespace characters. By default, whitespace characters match themselves. |
This regular expression matches any 11-12 digit phone number with optional group characters and (+) sign at the beginning:
Code language: SQL (Structured Query Language) (sql)
(+?( |-|.)?d{1,2}( |-|.)?)?((?d{3})?|d{3})( |-|.)?(d{3}( |-|.)?d{4})
Here is the explanation of the regular expression:
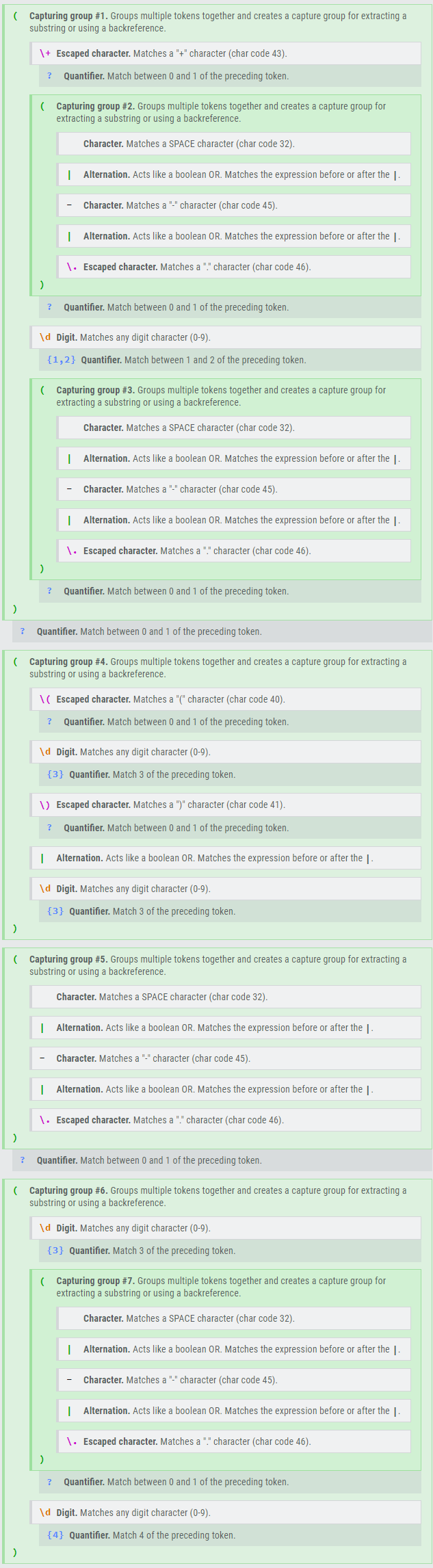
The following example uses the above regular expression to search for the first occurrence of a phone number in the string 'If you have any question please call 123-456-7890 or (123)-456-7891':
Code language: SQL (Structured Query Language) (sql)
SELECT REGEXP_INSTR( 'If you have any question please call 123-456-7890 or (123)-456-7891', '(+?( |-|.)?d{1,2}( |-|.)?)?((?d{3})?|d{3})( |-|.)?(d{3}( |-|.)?d{4})') First_Phone_No FROM dual;
Here is the output:
Code language: SQL (Structured Query Language) (sql)
FIRST_PHONE_NO --------------- 38
To find the second phone number in the string, you pass the position and occurrence arguments to the REGEXP_INSTR() function as follows:
Code language: SQL (Structured Query Language) (sql)
SELECT REGEXP_INSTR( 'If you have any question please call 123-456-7890 or (123)-456-7891', '(+?( |-|.)?d{1,2}( |-|.)?)?((?d{3})?|d{3})( |-|.)?(d{3}( |-|.)?d{4})', 1, 1) Second_Phone_No FROM dual;
The output is as follows:
Code language: SQL (Structured Query Language) (sql)
SECOND_PHONE_NO --------------- 54
In this tutorial, you have learned how to use the Oracle REGEXP_INSTR() function to search for a substring in a string using a regular expression pattern.
Was this tutorial helpful?
In Oracle, the REGEXP_INSTR() function searches a string for a regular expression pattern. It returns an integer indicating the beginning or ending position of the matched substring (whichever one you specify).
It extends the functionality of the INSTR() function by allowing us to use regular expression patterns.
Syntax
The syntax goes like this:
REGEXP_INSTR ( source_char, pattern
[, position
[, occurrence
[, return_opt
[, match_param
[, subexpr ]
]
]
]
]
)Where:
source_charis a character expression that serves as the search value.patternis the regular expression.positionis a positive integer that specifies where to begin the search. The default is1, meaning, start the search at the first character.occurrenceis a positive integer that specifies which occurrence to search for. The default is1, which means searches for the first occurrence.return_optspecifies whether Oracle should return the beginning or ending position of the matched substring. Use0for the beginning, and1for the ending. The default value is0.match_paramlets you change the default matching behaviour of the function. For example, it allows you to specify case-sensitivity, how multiple lines and spaces are dealt with, etc. This argument works the same as when used with theREGEXP_COUNT()function. See Oracle’s documentation for that function for more information.- For a
patternwith subexpressions,subexpris a nonnegative integer from 0 to 9 indicating which subexpression inpatternis to be returned by the function. This argument works the same as when used with theREGEXP_INSTR()function. See Oracle’s documentation for that function more information.
Example
Here’s a basic example of using REGEXP_INSTR() in Oracle:
SELECT
REGEXP_INSTR('My dogs are fluffy', 'd.g')
FROM DUAL;Result:
4
In this case there’s a match, and the beginning position of the substring is returned.
Regular expressions can be very powerful, and this example uses a very simple example. In order to use REGEXP_INSTR() effectively, you’ll need to know the correct pattern to use for the desired outcome.
No Match
Here’s an example where there’s no match:
SELECT REGEXP_INSTR('My dogs like dregs', 't.g')
FROM DUAL;Result:
0
There’s no match, so 0 is returned.
Multiple Matches
Here’s an example with multiple matches:
SELECT
REGEXP_INSTR('My dogs have dags', 'd.g')
FROM DUAL;Result:
4
It returned the position of the first occurrence.
However, you can specify which occurrence to replace:
SELECT
REGEXP_INSTR('My dogs have dags', 'd.g', 1, 2)
FROM DUAL;Result:
14
Note that I added two arguments here; 1 and 2. The 1 specifies whereabouts in the string to start the search (in this case, at the first character). The 2 is what specifies which occurrence to search for. In this case, the second occurrence is searched for.
Here’s what happens if I start the search after the first occurrence:
SELECT
REGEXP_INSTR('My dogs have dags', 'd.g', 8, 2)
FROM DUAL;Result:
0
In this case there’s no match, because there’s only one more occurrence after the starting position.
If I change the last argument to 1, then we get a match (because it’s the first occurrence after the specified starting position):
SELECT
REGEXP_INSTR('My dogs have dags', 'd.g', 8, 1)
FROM DUAL;Result:
14
Return the End Position
You can pass a fifth argument of either 0 or 1 to specify whether the function should return the beginning or end position of the substring.
The default value is 0 (for the beginning position). Here’s what happens if we specify 1:
SELECT
REGEXP_INSTR('My dogs are fluffy', 'd.g', 1, 1, 1)
FROM DUAL;Result:
7
Just to be clear, here it is again when compared with 0:
SELECT
REGEXP_INSTR('My dogs are fluffy', 'd.g', 1, 1, 0) AS "Start",
REGEXP_INSTR('My dogs are fluffy', 'd.g', 1, 1, 1) AS "End"
FROM DUAL;Result:
Start End
________ ______
4 7
Case Sensitivity
The REGEXP_INSTR() function follows Oracle’s collation determination and derivation rules, which define the collation to use when matching the string with the pattern.
However, you can explicitly specify case-sensitivity with the optional sixth argument. When you do this, it overrides any case-sensitivity or accent-sensitivity of the determined collation.
You can specify i for case-insensitive matching and c for case-sensitive matching.
Here’s an example:
SELECT
REGEXP_INSTR('My Cats', 'c.t', 1, 1, 0) AS "Default",
REGEXP_INSTR('My Cats', 'c.t', 1, 1, 0, 'i') AS "Case Insensitive",
REGEXP_INSTR('My Cats', 'c.t', 1, 1, 0, 'c') AS "Case Sensitive"
FROM DUAL;Result:
Default Case Insensitive Case Sensitive
__________ ___________________ _________________
0 4 0
My collation appears to be case-sensitive, based on these results. The other two strings were forced to a case-insensitive and case-sensitive matching respectively.
Subexpressions
Here’s an example of using the sixth argument to return a specific subexpression pattern:
SELECT REGEXP_INSTR(
'catdogcow',
'(c.t)(d.g)(c.w)',
1, 1, 0, 'i', 1
)
FROM DUAL;Result:
1
In this case I returned the first subexpression.
Here’s what happens if I specify the third subexpression:
SELECT REGEXP_INSTR(
'catdogcow',
'(c.t)(d.g)(c.w)',
1, 1, 0, 'i', 3
)
FROM DUAL;Result:
7
Null Arguments
With the exception of the 6th argument, providing null for an argument results in null:
SET NULL 'null';
SELECT
REGEXP_INSTR(null, 'c.t', 1, 1, 0, 'i', 1) AS "1",
REGEXP_INSTR('Cat', null, 1, 1, 0, 'i', 1) AS "2",
REGEXP_INSTR('Cat', 'c.t', null, 1, 0, 'i', 1) AS "3",
REGEXP_INSTR('Cat', 'c.t', 1, null, 0, 'i', 1) AS "4",
REGEXP_INSTR('Cat', 'c.t', 1, 1, null, 'i', 1) AS "5",
REGEXP_INSTR('Cat', 'c.t', 1, 1, 0, null, 1) AS "6",
REGEXP_INSTR('Cat', 'c.t', 1, 1, 0, 'i', null) AS "7"
FROM DUAL;Result:
1 2 3 4 5 6 7 _______ _______ _______ _______ _______ ____ _______ null null null null null 0 null
By default, SQLcl and SQL*Plus return a blank space whenever null occurs as a result of a SQL SELECT statement.
However, you can use SET NULL to specify a different string to be returned. Here I specified that the string null should be returned.
Wrong Number of Arguments
Passing no arguments to the function, or too few, results in an error:
SELECT REGEXP_INSTR()
FROM DUAL;Result:
Error starting at line : 1 in command - SELECT REGEXP_INSTR() FROM DUAL Error at Command Line : 1 Column : 8 Error report - SQL Error: ORA-00938: not enough arguments for function 00938. 00000 - "not enough arguments for function" *Cause: *Action:
The same applies when we pass too many arguments:
SELECT REGEXP_INSTR('Cat', 'c.t', 1, 1, 1, 'i', 1, 'oops')
FROM DUAL;Result:
Error starting at line : 1 in command -
SELECT REGEXP_INSTR('Cat', 'c.t', 1, 1, 1, 'i', 1, 'oops')
FROM DUAL
Error at Command Line : 1 Column : 8
Error report -
SQL Error: ORA-00939: too many arguments for function
00939. 00000 - "too many arguments for function"
*Cause:
*Action:
More Information
The REGEXP_INSTR() function (as well as Oracle’s other implementation of regular expressions) conforms with the IEEE Portable Operating System Interface (POSIX) regular expression standard and to the Unicode Regular Expression Guidelines of the Unicode Consortium.
See the Oracle documentation for more information and examples of the REGEXP_INSTR() function.
 В Oracle10g в области работы со строками произошли очень серьезные изменения: была реализована поддержка регулярных выражений. Причем речь идет не об упрощенной поддержке регулярных выражений вроде предиката LIKE, которая встречается в других СУБД. Компания Oracle предоставила в наше распоряжение отлично проработанный, мощный набор функций — то, что было необходимо в PL/SQL.
В Oracle10g в области работы со строками произошли очень серьезные изменения: была реализована поддержка регулярных выражений. Причем речь идет не об упрощенной поддержке регулярных выражений вроде предиката LIKE, которая встречается в других СУБД. Компания Oracle предоставила в наше распоряжение отлично проработанный, мощный набор функций — то, что было необходимо в PL/SQL.
Регулярные выражения образуют своего рода язык для описания и обработки текста. Читатели, знакомые с языком Perl, уже разбираются в этой теме, поскольку Perl способствовал распространению регулярных выражений в большей степени, чем любой другой язык. Поддержка регулярных выражений в Oracle10g довольно близко соответствовала стандарту регулярных выражений POSIX (Portable Operating System Interface). В Oracle10g Release 2 появилась поддержка многих нестандартных, но весьма полезных операторов из мира Perl, а в Oracle11g возможности регулярных выражений были дополнительно расширены.
Проверка наличия совпадения
Регулярные выражения используются для описания текста, который требуется найти в строке (и возможно, подвергнуть дополнительной обработке). Давайте вернемся к примеру, который приводился ранее в этом блоге:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Aaron,Jeff';
Допустим, мы хотим определить на программном уровне, содержит ли строка список имен, разделенных запятыми. Для этого мы воспользуемся функцией REGEXP_LIKE, обнаруживающей совпадения шаблона в строке:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
BEGIN
--Поиск по шаблону
comma_delimited := REGEXP_LIKE(names,'^([a-z A-Z]*,)+([a-z A-Z]*){1}$');
--Вывод результата
DBMS_OUTPUT.PUT_LINE(
CASE comma_delimited
WHEN true THEN 'Обнаружен список с разделителями!'
ELSE 'Совпадение отсутствует.'
END);
END;
Результат:
Обнаружен список с разделителями
Чтобы разобраться в происходящем, необходимо начать с выражения, описывающего искомый текст. Общий синтаксис функции REGEXP_LIKE выглядит так:
REGEXP_LIKE (исходная_строка, шаблон [,модификаторы])
Здесь исходная_строка — символьная строка, в которой ищутся совпадения; шаблон — регулярное выражение, совпадения которого ищутся в исходной_строке; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Если функция REGEXP_LIKE находит совпадение шаблона в исходной_строке, она возвращает логическое значение TRUE; в противном случае возвращается FALSE.
Процесс построения регулярного выражения выглядел примерно так:
[a-z A-Z]Каждый элемент списка имен может состоять только из букв и пробелов. Квадратные скобки определяют набор символов, которые могут входить в совпадение. Диапазон a–z описывает все буквы нижнего регистра, а диапазон A–Z — все буквы верхнего регистра. Пробел находится между двумя компонентами выражения. Таким образом, этот шаблон описывает один любой символ нижнего или верхнего регистра или пробел.[a-z A-Z]* Звездочка является квантификатором — служебным символом, который указывает, что каждый элемент списка содержит ноль или более повторений совпадения, описанного шаблоном в квадратных скобках.[a-z A-Z]*, Каждый элемент списка должен завершаться запятой. Последний элемент является исключением, но пока мы не будем обращать внимания на эту подробность.([a-z A-Z]*,) Круглые скобки определяют подвыражение, которое описывает некоторое количество символов, завершаемых запятой. Мы определяем это подвыражение, потому что оно должно повторяться при поиске.([a-z A-Z]*,)+ Знак + — еще один квантификатор, применяемый к предшествующему элементу (то есть к подвыражению в круглых скобках). В отличие от * знак + означает «одно или более повторений». Список, разделенный запятыми, состоит из одного или нескольких повторений подвыражения.- (
[a-z A-Z]*,)+([a-z A-Z]*)В шаблон добавляется еще одно подвыражение: ([a-z A-Z]*). Оно почти совпадает с первым, но не содержит запятой. Последний элемент списка не завершается запятой. ([a-z A-Z]*,)+([a-z A-Z]*){1}Мы добавляем квантификатор {1}, чтобы разрешить вхождение ровно одного элемента списка без завершающей запятой.- ^
([a-z A-Z]*,)+([a-z A-Z]*){1}$Наконец, метасимволы ^ и$привязывают потенциальное совпадение к началу и концу целевой строки. Это означает, что совпадением шаблона может быть только вся строка вместо некоторого подмножества ее символов.
Функция REGEXP_LIKE анализирует список имен и проверяет, соответствует ли он шаблону. Эта функция оптимизирована для простого обнаружения совпадения шаблона в строке, но другие функции способны на большее!
Поиск совпадения
Функция REGEXP_INSTR используется для поиска совпадений шаблона в строке. Общий синтаксис REGEXP_INSTR:
REGEXP_INSTR (исходная_строка, шаблон [,начальная_позиция [,номер [,флаг_возвращаемого_ значения [,модификаторы [,подвыражение]]]]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; номер — порядковый номер совпадения (1 = первое, 2 = второе и т. д.); флаг_возвращаемого_значения — 0 для начальной позиции или 1 для конечной позиции совпадения; модификаторы — один или несколько модификаторов, управляющих процессом поиска (например, i для поиска без учета регистра). Начиная с Oracle11g, также можно задать параметр подвыражение (1 = первое, 2 = второе и т. д.), чтобы функция REGEXP_INST возвращала начальную позицию заданного подвыражения (части шаблона, заключенной в круглые скобки).
Например, чтобы найти первое вхождение имени, начинающегося с буквы A и завершающегося согласной буквой, можно использовать следующее выражение:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron'; names_adjusted VARCHAR2(61); comma_delimited BOOLEAN; j_location NUMBER; BEGIN -- Поиск по шаблону comma_delimited := REGEXP_LIKE(names,'^([a-z ]*,)+([a-z ]*)$', 'i'); -- Продолжить, только если действительно был обнаружен список, -- разделенный запятыми. IF comma_delimited THEN j_location := REGEXP_INSTR(names, 'A[a-z]*[^aeiou],|A[a-z]*[^aeiou]$'); DBMS_OUTPUT.PUT_LINE( J_location); END IF; END;
При выполнении этого фрагмента выясняется, что имя на букву A, завершающееся согласной (Andrew), начинается в позиции 22. А вот как проходило построение шаблона:
AСовпадение начинается с буквы A. Беспокоиться о запятых не нужно — на этой стадии мы уже знаем, что работаем со списком, разделенным запятыми.A[a-z ]*За буквой A следует некоторое количество букв или пробелов. Квантификатор * указывает, что за буквой A следует ноль или более таких символов.A[a-z ]*[^aeiou]В выражение включается компонент [^aeiou], чтобы имя могло заканчиваться любым символом, кроме гласной. Знак ^ инвертирует содержимое квадратных скобок —
совпадает любой символ, кроме гласной буквы. Так как квантификатор не указан, требуется присутствие ровно одного такого символа.A[a-z ]*[^aeiou],Совпадение должно завершаться запятой; в противном случае шаблон найдет совпадение для подстроки «An» в имени «Anna». Хотя добавление запятой решает эту проблему, тут же возникает другая: шаблон не найдет совпадение для имени «Aaron» в конце строки.A[a-z ]*[^aeiou],|A[a-z ]*[^aeiou]$В выражении появляется вертикальная черта (|), обозначение альтернативы: общее совпадение находится при совпадении любого из вариантов. Первый вариант завершается запятой, второй — нет. Второй вариант учитывает возможность того, что текущее имя стоит на последнем месте в списке, поэтому он привязывается к концу строки метасимволом$.
Регулярные выражения — далеко не простая тема! Новички часто сталкиваются с нюансами обработки регулярных выражений, которые часто преподносят неприятные сюрпризы. Я потратил некоторое время на работу над этим примером и несколько раз зашел в тупик, прежде чем выйти на правильный путь. Не отчаивайтесь — с опытом писать регулярные выражения становится проще.
Функция REGEXP_INSTR приносит пользу в некоторых ситуациях, но обычно нас больше интересует текст совпадения, а не информация о его положении в строке.
Получение текста совпадения
Для демонстрации получения текста совпадения мы воспользуемся другим примером. Телефонные номера строятся по определенной схеме, но у этой схемы существует несколько разновидностей. Как правило, телефонный номер начинается с кода города (три цифры), за которым следует код станции (три цифры) и локальный номер (четыре цифры). Таким образом, телефонный номер представляет собой строку из 10 цифр. Однако существует много альтернативных способов представления числа. Код города может быть заключен в круглые скобки и обычно (хотя и не всегда) отделяется от остального номера пробелом, точкой или дефисом. Код станции обычно (но тоже не всегда) отделяется от локального номера пробелом, точкой или дефисом. Таким образом, любая из следующих форм записи телефонного номера является допустимой:
7735555253 773-555-5253 (773)555-5253 (773) 555 5253 773.555.5253
С подобными нежесткими схемами записи легко работать при помощи регулярных выражений, но очень трудно без них. Мы воспользуемся функцией REGEXP_SUBSTR для извлечения телефонного номера из строки с контактными данными:
DECLARE
contact_info VARCHAR2(200) := '
address:
1060 W. Addison St.
Chicago, IL 60613
home 773-555-5253
';
phone_pattern VARCHAR2(90) :=
'(?d{3})?[[:space:].-]?d{3}[[:space:].-]?d{4}';
BEGIN
DBMS_OUTPUT.PUT_LINE('Номер телефона: '||
REGEXP_SUBSTR(contact_info,phone_pattern,1,1));
END;
Результат работы программы:
Номер телефона: 773-555-5253
Ого! Шаблон получился довольно устрашающим. Давайте разобьем его на составляющие:
(?Шаблон начинается с необязательного символа открывающей круглой скобки. Так как круглые скобки в языке регулярных выражений являются метасимволами (то есть имеют специальное значение), для использования в качестве литерала символ круглой скобки необходимо экранировать (escape), поставив перед ним символ (обратная косая черта). Вопросительный знак — квантификатор, обозначающий ноль или одно вхождение предшествующего символа. Таким образом, эта часть выражения описывает необязательный символ открывающей круглой скобки.-
d{3} d— один из операторов, появившихся в Oracle10g Release 2 под влиянием языка Perl. Он обозначает произвольную цифру. Квантификатор {} указывает, что предшествующий символ входит в шаблон заданное количество раз (в данном случае три). Эта часть шаблона описывает три цифры. )?Необязательный символ закрывающей круглой скобки.-
[[:space:].-]?В квадратных скобках перечисляются символы, для которых обнаруживается совпадение — в данном случае это пропуск, точка или дефис. Конструкция [:space:] обозначает символьный классPOSIXдля пропускных символов (пробел, табуляция, новая строка) в текущем наборе NLS. Точка и дефис являются метасимволами, поэтому в шаблоне их необходимо экранировать обратной косой чертой. Наконец, ? означает ноль или одно вхождение предшествующего символа. Эта часть шаблона описывает необязательный пропуск, точку или дефис. d{3}Эта часть шаблона описывает три цифры (см. выше).[[:space:].-]?Эта часть шаблона описывает необязательный пропуск, точку или дефис (см. выше).d{4}Четыре цифры (см. выше).
Обязательно комментируйте свой код, использующий регулярные выражения, — это пригодится тому, кто будет разбираться в нем (вполне возможно, это будете вы сами через полгода).
Общий синтаксис REGEXP_SUBSTR:
REGEXP_SUBSTR (исходная_строка, шаблон [,начальная_позиция [,номер [,модификаторы [,подвыражение]]]])
Функция REGEXP_SUBSTR возвращает часть исходной_строки, совпадающую с шаблоном или подвыражением. Если совпадение не обнаружено, функция возвращает NULL. Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; номер — порядковый номер совпадения (1 = первое, 2 = второе и т. д.); модификаторы — один или несколько модификаторов, управляющих процессом поиска.
Начиная с Oracle11g, также можно задать параметр подвыражение (1 = первое, 2 = второе и т. д.), чтобы функция возвращала начальную позицию заданного подвыражения (части шаблона, заключенной в круглые скобки). Подвыражения удобны в тех случаях, когда требуется найти совпадение для всего шаблона, но получить совпадение только для его части. Скажем, если мы хотим найти телефонный номер и извлечь из него код города, мы заключаем часть шаблона, описывающую код города, в круглые скобки, превращая ее в подвыражение:
DECLARE
contact_info VARCHAR2(200) := '
address:
1060 W. Addison St.
Chicago, IL 60613
home 773-555-5253
work (312) 555-1234
cell 224.555.2233
';
phone_pattern VARCHAR2(90) :=
'(?(d{3}))?[[:space:].-]?d{3}[[:space:].-]?d{4}';
contains_phone_nbr BOOLEAN;
phone_number VARCHAR2(15);
phone_counter NUMBER;
area_code VARCHAR2(3);
BEGIN
contains_phone_nbr := REGEXP_LIKE(contact_info,phone_pattern);
IF contains_phone_nbr THEN
phone_counter := 1;
DBMS_OUTPUT.PUT_LINE('Номера:');
LOOP
phone_number := REGEXP_SUBSTR(contact_info,phone_pattern,1,phone_counter);
EXIT WHEN phone_number IS NULL; -- NULL означает отсутствие совпадений
DBMS_OUTPUT.PUT_LINE(phone_number);
phone_counter := phone_counter + 1;
END LOOP;
phone_counter := 1;
DBMS_OUTPUT.PUT_LINE('Коды городов:');
LOOP
area_code := REGEXP_SUBSTR(contact_info,phone_pattern,1,phone_
counter,'i',1);
EXIT WHEN area_code IS NULL;
DBMS_OUTPUT.PUT_LINE(area_code);
phone_counter := phone_counter + 1;
END LOOP;
END IF;
END;
Этот фрагмент выводит телефонные номера и коды городов:
Номера:
773-555-5253
(312) 555-1234
224.555.2233
Коды городов:
773
312
224
Подсчет совпадений
Еще одна типичная задача — подсчет количества совпадений регулярного выражения в строке. До выхода Oracle11g программисту приходилось в цикле перебирать и подсчитывать совпадения. Теперь для этого можно воспользоваться новой функцией REGEXP_COUNT. Общий синтаксис ее вызова:
REGEXP_COUNT (исходная_строка, шаблон [,начальная_позиция [,модификаторы ]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; модификаторы — один или несколько модификаторов, управляющих процессом поиска.
DECLARE
contact_info VARCHAR2(200) := '
address:
1060 W. Addison St.
Chicago, IL 60613
home 773-555-5253
work (312) 123-4567';
phone_pattern VARCHAR2(90) :=
'(?(d{3}))?[[:space:].-]?(d{3})[[:space:].-]?d{4}';
BEGIN
DBMS_OUTPUT.PUT_LINE('Обнаружено '
||REGEXP_COUNT(contact_info,phone_pattern)
||' телефонных номера');
END;
Результат:
Обнаружено 2 телефонных номера
Замена текста REGEXP_REPLACE
Поиск и замена — одна из лучших областей применения регулярных выражений. Текст замены может включать ссылки на части исходного выражения (называемые обратными ссылками), открывающие чрезвычайно мощные возможности при работе с текстом. Допустим, имеется список имен, разделенный запятыми, и его содержимое необходимо вывести по два имени в строке. Одно из решений заключается в том, чтобы заменить каждую вторую запятую символом новой строки. Сделать это при помощи стандартной функции REPLACE нелегко, но с функцией REGEXP_REPLACE задача решается просто. Общий синтаксис ее вызова:
REGEXP_REPLACE (исходная_строка, шаблон [,строка_замены [,начальная_позиция [,номер [,модификаторы ]]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Пример:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
extracted_name VARCHAR2(60);
name_counter NUMBER;
BEGIN
-- Искать совпадение шаблона
comma_delimited := REGEXP_LIKE(names,'^([a-z ]*,)+([a-z ]*){1}$', 'i');
-- Продолжать, только если мы действительно
-- работаем со списком, разделенным запятыми.
IF comma_delimited THEN
names := REGEXP_REPLACE(
names,
'([a-z A-Z]*),([a-z A-Z]*),',
'1,2' || chr(10) );
END IF;
DBMS_OUTPUT.PUT_LINE(names);
END;
Результат выглядит так:
Anna,Matt Joe,Nathan Andrew,Jeff Aaron
При вызове функции REGEXP_REPLACE передаются три аргумента:
- names — исходная строка;
- ‘([a-z A-Z]*),([a-z A-Z]*),’ — выражение, описывающее заменяемый текст (см. ниже);
- ‘1,2 ‘ || chr(10) — текст замены. 1 и 2 — обратные ссылки, заложенные в основу нашего решения. Подробные объяснения также приводятся ниже.
Выражение, описывающее искомый текст, состоит из двух подвыражений в круглых скобках и двух запятых.
([a-z A-Z]*)Совпадение должно начинаться с имени.,За именем должна следовать запятая.([a-z A-Z]*)Затем идет другое имя.,И снова одна запятая.
Наша цель — заменить каждую вторую запятую символом новой строки. Вот почему выражение написано так, чтобы оно совпадало с двумя именами и двумя запятыми. Также запятые не напрасно выведены за пределы подвыражений.
Первое совпадение для нашего выражения, которое будет найдено при вызове REGEXP_REPLACE, выглядит так:
Anna,Matt,
Два подвыражения соответствуют именам «Anna» и «Matt». В основе нашего решения лежит возможность ссылаться на текст, совпавший с заданным подвыражением, через обратную ссылку. Обратные ссылки 1 и 2 в тексте замены ссылаются на текст, совпавший с первым и вторым подвыражением. Вот что происходит:
'1,2' || chr(10) -- Текст замены
'Anna,2' || chr(10) -- Подстановка текста, совпавшего
-- с первым подвыражением
'Anna,Matt' || chr(10) -- Подстановка текста, совпавшего
-- со вторым подвыражением
Вероятно, вы уже видите, какие мощные инструменты оказались в вашем распоряжении. Запятые из исходного текста попросту не используются. Мы берем текст, совпавший с двумя подвыражениями (имена «Anna» и «Matt»), и вставляем их в новую строку с одной запятой и одним символом новой строки.
Но и это еще не все! Текст замены легко изменить так, чтобы вместо запятой в нем использовался символ табуляции (ASCII-код 9):
names := REGEXP_REPLACE( names, '([a-z A-Z]*),([a-z A-Z]*),', '1' || chr(9) || '2' || chr(10) );
Теперь результаты выводятся в два аккуратных столбца:
Anna Matt Joe Nathan Andrew Jeff Aaron
Поиск и замена с использованием регулярных выражений — замечательная штука. Это мощный и элегантный механизм, с помощью которого можно сделать очень многое.
Максимализм и минимализм
Концепции максимализма и минимализма играют важную роль при написании регулярных выражений. Допустим, из разделенного запятыми списка имен нужно извлечь только первое имя и следующую за ним запятую. Список, уже приводившийся ранее, выглядит так:
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
Казалось бы, нужно искать серию символов, завершающуюся запятой:
.*,
Давайте посмотрим, что из этого получится:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron'; BEGIN DBMS_OUTPUT.PUT_LINE( REGEXP_SUBSTR(names, '.*,') ); END;
Результат выглядит так:
Anna,Matt,Joe,Nathan,Andrew,Jeff,
Совсем не то. Что произошло? Дело в «жадности» регулярных выражений: для каждого элемента регулярного выражения подыскивается максимальное совпадение, состоящее из как можно большего количества символов. Когда мы с вами видим конструкцию:
.*,
у нас появляется естественное желание остановиться у первой запятой и вернуть строку «Anna,». Однако база данных пытается найти самую длинную серию символов, завершающуюся запятой; база данных останавливается не на первой запятой, а на последней.
В версии Oracle Database 10g Release 1, в которой впервые была представлена поддержка регулярных выражений, возможности решения проблем максимализма были весьма ограничены. Иногда проблему удавалось решить изменением формулировки регулярного выражения — например, для выделения первого имени с завершающей запятой можно использовать выражение [^,]*,. Однако в других ситуациях приходилось менять весь подход к решению, часто вплоть до применения совершенно других функций.
Начиная с Oracle Database 10g Release 2, проблема максимализма отчасти упростилась с введением минимальных квантификаторов (по образцу тех, которые поддерживаются в Perl). Добавляя вопросительный знак к квантификатору после точки, то есть превращая * в *?, я ищу самую короткую последовательность символов перед запятой:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron'; BEGIN DBMS_OUTPUT.PUT_LINE( REGEXP_SUBSTR(names, '(.*?,)') ); END;
Теперь результат выглядит так, как и ожидалось:
Anna,
Минимальные квантификаторы останавливаются на первом подходящем совпадении, не пытаясь захватить как можно больше символов.
Подробнее о регулярных выражениях
Регулярные выражения на первый взгляд просты, но эта область на удивление глубока и нетривиальна. Они достаточно просты, чтобы вы начали пользоваться ими после прочтения этой статьи (хочется надеяться!), и все же вам предстоит очень много узнать. Некоторые источники информации от компании Oracle и издательства O’Reilly:
- Oracle Database Application Developer’s Guide — Fundamentals. В главе 4 этого руководства описана поддержка регулярных выражений в Oracle.
- Oracle Regular Expression Pocket Reference
.Хороший вводный учебник по работе с регулярными выражениями; авторы — Джонатан Дженник ( Jonathan Gennick) и Питер Линсли (Peter Linsley). Питер является одним из разработчиков реализации регулярных выражений Oracle. - Mastering Oracle SQL. Одна из глав книги посвящена регулярным выражениям в контексте Oracle SQL. Отличный учебник для всех, кто хочет поднять свои навыки использования SQL на новый уровень.
- Mastering Regular Expressions. Книга Джеффри Фридла ( Jeffrey Friedl) считается самым авторитетным источником информации об использовании регулярных выражений. Если вы хотите действительно глубоко изучить материал — читайте книгу Фридла.
Вас заинтересует / Intresting for you:
В посте рассматриваются однострочные функции SUBSTR и INSTR, работающие с символьными данными.
Символьные данные или строки являются универсальными, т.к. они позволяют хранить практически любой тип данных. Функции, которые работают с символьными данными, классифицируются на функции преобразования регистра символов и манипулирования символами.
Функции манипулирования символами используются для извлечения, преобразования и форматирования символьных строк. К этому классу относятся функции CONCAT, LENGTH, LPAD, RPAD, TRIM, REPLACE и рассматриваемые нижу функции SUBSTR и INSTR.
Функция SUBSTR принимает три параметра и возвращает строку, состоящую из количества символов, извлеченных из исходной строки, начиная с указанной начальной позиции:
SUBSTR (строка, начальная позиция, количество символов).
В приведенном примере извлекаются символы с первой по четвертую позиции из значений колонки last_name. Для сравнения выводятся исходные значения колонки last_name.
SELECT last_name, SUBSTR (last_name, 1, 4) FROM employees

Функция
INSTR возвращает число, представляющее позицию в исходной строке, начиная с
заданной начальной позиции, где n-ное вхождение элемента поиска начинается:
INSTR (строка, элемент поиска, [начальная позиция], [n-ное вхождение элемента поиска]
Следующий запрос показывает позицию строчной буквы a для каждой строки колонки last_name. Если в строке встречаются два или более символов a, то будет отображена позиция первого/начального из них. Для сравнения и анализа выводятся исходные значения колонки.
SELECT last_name, INSTR ( last_name,'a') FROM employees

Если необходимо также отобразить позицию заглавной буквы А в фамилии, то надо предварительно перевести все символы фамилии в строчные, используя вложенную функцию LOWER. Запрос выглядит следующим образом:
SELECT last_name, INSTR (LOWER(last_name, 'a') FROM employees

Как видно из результата, теперь позиция заглавной буквы A тоже определяется, например, для Abel, Ande, Atkinson, Austin возвращается значение 1.
В посте приведен пример совместного применения таких функций, как LENGTH, SUBSTR и INSTR.