In this article, we are going to discuss how to find the maximum value and its index position in columns and rows of a Dataframe.
Create Dataframe to Find max values & position of columns or rows
Python3
import numpy as np
import pandas as pd
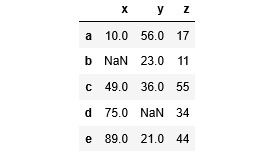
matrix = [(10, 56, 17),
(np.NaN, 23, 11),
(49, 36, 55),
(75, np.NaN, 34),
(89, 21, 44)
]
abc = pd.DataFrame(matrix, index=list('abcde'), columns=list('xyz'))
abc
Output:
Time complexity: O(n) where n is the number of elements in the matrix.
Auxiliary space: O(n) where n is the number of elements in the matrix.
Find maximum values in columns and rows in Pandas
Pandas dataframe.max() method finds the maximum of the values in the object and returns it. If the input is a series, the method will return a scalar which will be the maximum of the values in the series. If the input is a Dataframe, then the method will return a series with a maximum of values over the specified axis in the Dataframe. The index axis is the default axis taken by this method.
Get the maximum values of every column in Python
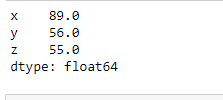
To find the maximum value of each column, call the max() method on the Dataframe object without taking any argument. In the output, We can see that it returned a series of maximum values where the index is the column name and values are the maxima from each column.
Python3
maxValues = abc.max()
print(maxValues)
Output:
Get max value from a row of a Dataframe in Python
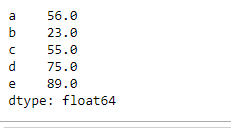
For the maximum value of each row, call the max() method on the Dataframe object with an argument axis=1. In the output, we can see that it returned a series of maximum values where the index is the row name and values are the maxima from each row.
Python3
maxValues = abc.max(axis=1)
print(maxValues)
Output:
Get the maximum values of every column without skipping NaN in Python
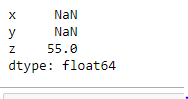
From the above examples, NaN values are skipped while finding the maximum values on any axis. By putting skipna=False we can include NaN values also. If any NaN value exists it will be considered as the maximum value.
Python3
maxValues = abc.max(skipna=False)
print(maxValues)
Output:
Get maximum values from multiple columns in Python
To get the maximum value of a single column see the following example
Python3
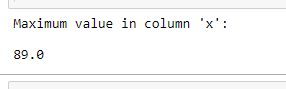
maxClm = df['x'].max()
print("Maximum value in column 'x': ")
print(maxClm)
Output:
Get max value in one or more columns
A list of columns can also be passed instead of a single column to find the maximum values of specified columns
Python3
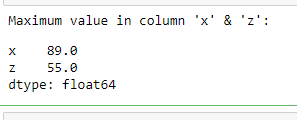
maxValues = df[['x', 'z']].max()
print("Maximum value in column 'x' & 'z': ")
print(maxValues)
Output:
Find the maximum position in columns and rows in Pandas
Pandas dataframe.idxmax() method returns the index of the first occurrence of maximum over the requested axis. While finding the index of the maximum value across any index, all NA/null values are excluded.
Find the row index which has the maximum value
It returns a series containing the column names as index and row as index labels where the maximum value exists in that column.
Python3
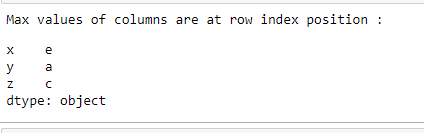
maxValueIndex = df.idxmax()
print("Maximum values of columns are at row index position :")
print(maxValueIndex)
Output:
Find the column name which has the maximum value
It returns a series containing the rows index labels as index and column names as values where the maximum value exists in that row.
Python3
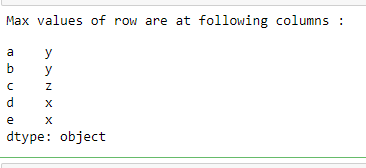
maxValueIndex = df.idxmax(axis=1)
print("Max values of row are at following columns :")
print(maxValueIndex)
Output:
Last Updated :
03 Feb, 2023
Like Article
Save Article
Как найти минимальное и максимальное значение в Pandas

Нахождение максимального и минимального значения в Pandas — зачастую, необходимая операция для анализа данных. Поэтому предлагаю попрактиковаться на примере тренировочного датасета: отыскать предельные значения и вывести строки с этими значениями на экран.
Действовать будем по плану:
Сначала поработаем с максимальными значениями:
- Найдем максимальное значение:
- для каждого столбца таблицы;
- в определенном столбце таблицы
- Выведем на экран строки с максимальными значениями
Затем поработаем с минимальными значениями:
- Найдем минимальное значение:
- для каждого столбца таблицы;
- в определенном столбце таблицы
- Выведем на экран строки с минимальными значениями
Загрузка датасета
Для наглядности будем использовать тренировочный датасет с пропорциями некоторых продуктов для приготовления кондитерских изделий. Скачать датасет можно по ссылке: products.csv. Итак, загрузим файл с данными:
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
Выведем таблицу на экран:
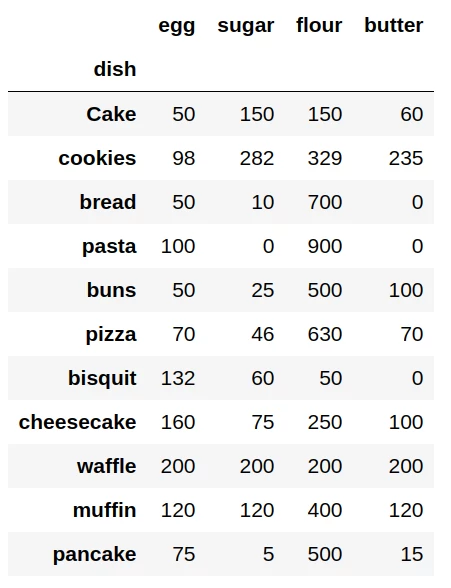
Названия десертов и наименования продуктов представлены в качестве индексов таблицы. Числовое значение в каждой ячейке, расположенной на пересечении строки с десертом и колонки с наименованием продукта — это количество продукта в граммах, необходимое для приготовления 1 кг. изделия.
После загрузки датасета можно переходить к реализации нашего плана и отыскать предельные значения!
Работаем с максимальными значениями
1. Ищем максимальное значение:
# для каждого столбца таблицы:
Получим максимальный вес каждого продукта. Для этого найдем максимальные значения в каждом столбце таблицы с помощью функции max() и выведем их на экран. Применим функцию max() ко всей таблице data:
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
#Получим максимальные значения в каждом столбце
maximums = data.max()
# выведем результат на экран
print(maximums)
Полученный результат — максимальные значения в каждом столбце
egg 200 sugar 282 flour 900 butter 235 dtype: int64
# в определенном столбце таблицы:
Узнаем, сколько потребуется сахара для приготовления 1 кг. самого сладкого блюда из представленных в таблице. Для этого получим максимальное значение в столбце «sugar» с помощью функции max(). На этот раз применим функцию max() к столбцу «sugar»:
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
#Получим максимальное значение в столбце "sugar"
max_sugar = data['sugar'].max()
# выведем результат на экран
print(max_sugar)
Полученный результат — максимальное значение в столбце «sugar»
282
Теперь мы знаем, что в 1 кг. самого сладкого блюда из таблицы data содержится 282 грамм сахара. Однако, хотелось бы узнать название этого блюда, а еще лучше — вывести всю строку с информацией о нем:
2. Выводим на экран строку с максимальным значением
Для этого используем полученное значение с максимальным количеством сахара (data[‘sugar’].max()) и выведем строку, для которой выполняется условие data[‘sugar’]==data[‘sugar’].max():
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
# Найдем строку с максимальным значением
str = data[data['sugar']==data['sugar'].max()]
# Выведем строку на экран
print(str)
Полученный результат — строка таблицы data с максимальным значением

В соответствии с полученным результатом, самым сладким блюдом из представленных в таблице data являются печенья!
Работаем с минимальными значениями
Главным козырем при нахождении минимальных значений в данных является функция min(). Рассмотрим варианты ее применения для получения желаемого результата:
1. Ищем минимальное значение:
# для каждого столбца таблицы
Выведем на экран минимальные значения в каждом столбце таблицы с помощью функции min(). Для этого применим функцию min() ко всей таблице data:
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
# Найдем минимальные значения в каждом столбце таблицы
minimums = data.min()
# Выведем результат на экран
print(minimums)
Полученный результат — минимальные значения в каждом столбце
egg 50 sugar 0 flour 50 butter 0 dtype: int64
# в определенном столбце таблицы:
Найдем минимальное значение в столбце «sugar» с помощью функции min():
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
# Найдем минимальное значение в столбце «sugar»
min_sugar = data['sugar'].min()
# Выведем найденное значение на экран
print(min_sugar)
Результат на экране — минимальное значение в столбце «sugar»:
0
Выходит, что среди размещенных в таблице блюд присутствуют несладкие изделия. Давайте узнаем, какой представитель выпечки самый несладкий: выведем на экран строку с его именем!
2. Выводим на экран строку с минимальным значением
Для этого найдем строку, для которой значение в столбце ‘sugar’ совпадает с найденным ранее минимальным количеством сахара: data[‘sugar’]==data[‘sugar’].min():
import pandas as pd
data = pd.read_csv('products.csv', sep=';', index_col='dish')
data.head(11)
# Найдем строку с минимальным значением
str = data[data['sugar']==data['sugar'].min()]
# выведем строку на экран
print(str)
Результат — строка с минимальным значением в столбце «sugar»:
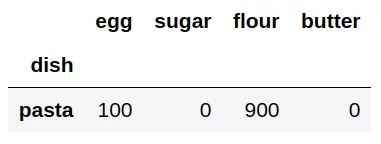
Таким образом, нам удалось выяснить, что в пасте (в соответствии с таблицей data) не содержится сахара. Ах, вот почему она не сладкая! 😉
Теперь, когда все технологические секреты раскрыты, а предельные значения найдены, подведем итоги:

У нас появился Telegram-канал для изучающих Python! Подписывайтесь по ссылке: «Кодим на Python! Вместе «питонить» веселее! 😉
Коротко о поиске максимальных и минимальных значений в pandas:
Дано: датасет data c числовыми значениями в столбцах: «egg», «sugar», «flour», «butter».
1. Получим максимальные / минимальные значения для каждого столбца:
# Максимальные значения - maximums maximums = data.max() # Минимальные значения - minimums minimums = data.min()
2. Получим максимальное / минимальное значение для столбца «sugar»:
# Максимальное значение в столбце "sugar" max_sugar = data['sugar'].max() # Минимальное значение в столбце "sugar" min_sugar = data['sugar'].min()
3. Выведем на экран строку с максимальным / минимальным значением в столбце «sugar»:
# Найдем строку с максимальным значением str = data[data['sugar']==data['sugar'].max()] # выведем строку на экран print(str) # Найдем строку с минимальным значением str = data[data['sugar']==data['sugar'].min()] # выведем строку на экран print(str)
Pandas dataframes are great for analyzing and manipulating data. In this tutorial, we will look at how to get the max value in one or more columns of a pandas dataframe with the help of some examples.
If you prefer a video tutorial over text, check out the following video detailing the steps in this tutorial –
Pandas max() function
You can use the pandas max() function to get the maximum value in a given column, multiple columns, or the entire dataframe. The following is the syntax:
# df is a pandas dataframe # max value in a column df['Col'].max() # max value for multiple columns df[['Col1', 'Col2']].max() # max value for each numerical column in the dataframe df.max(numeric_only=True) # max value in the entire dataframe df.max(numeric_only=True).max()
It returns the maximum value or values depending on the input and the axis (see the examples below).
Examples
Let’s look at some use-case of the pandas max() function. First, we’ll create a sample dataframe that we will be using throughout this tutorial.
import numpy as np
import pandas as pd
# create a pandas dataframe
df = pd.DataFrame({
'Name': ['Neeraj Chopra', 'Jakub Vadlejch', 'Vitezslav Vesely', 'Julian Weber', 'Arshad Nadeem'],
'Country': ['India', 'Czech Republic', 'Czech Republic', 'Germany', 'Pakistan'],
'Attempt1': [87.03, 83.98, 79.79, 85.30, 82.40],
'Attempt2': [87.58, np.nan, 80.30, 77.90, np.nan],
'Attempt3': [76.79, np.nan, 85.44, 78.00, 84.62],
'Attempt4': [np.nan, 82.86, np.nan, 83.10, 82.91],
'Attempt5': [np.nan, 86.67, 84.98, 85.15, 81.98],
'Attempt6': [84.24, np.nan, np.nan, 75.72, np.nan]
})
# display the dataframe
df
Output:

Here we created a dataframe containing the scores of the top five performers in the men’s javelin throw event final at the Tokyo 2020 Olympics. The attempts represent the throw of the javelin in meters.
1. Max value in a single pandas column
To get the maximum value in a pandas column, use the max() function as follows. For example, let’s get the maximum value achieved in the first attempt.
# max value in Attempt1 print(df['Attempt1'].max())
Output:
87.03
We get 87.03 meters as the maximum distance thrown in the “Attemp1”
Note that you can get the index corresponding to the max value with the pandas idxmax() function. Let’s get the name of the athlete who threw the longest in the first attempt with this index.
# index corresponding max value i = df['Attempt1'].idxmax() print(i) # display the name corresponding this index print(df['Name'][i])
Output:
0 Neeraj Chopra
You can see that the max value corresponds to “Neeraj Chopra”.
2. Max value in two pandas columns
You can also get the max value of multiple pandas columns with the pandas min() function. For example, let’s find the maximum values in “Attempt1” and “Attempt2” respectively.
# get max values in columns "Attempt1" and "Attempt2" print(df[['Attempt1', 'Attempt2']].max())
Output:
Attempt1 87.03 Attempt2 87.58 dtype: float64
Here, created a subset dataframe with the columns we wanted and then applied the max() function. We get the maximum value for each of the two columns.
3. Max value for each column in the dataframe
Similarly, you can get the max value for each column in the dataframe. Apply the max function over the entire dataframe instead of a single column or a selection of columns. For example,
# get max values in each column of the dataframe print(df.max())
Output:
Name Vitezslav Vesely Country Pakistan Attempt1 87.03 Attempt2 87.58 Attempt3 85.44 Attempt4 83.1 Attempt5 86.67 Attempt6 84.24 dtype: object
We get the maximum values in each column of the dataframe df. Note that we also get max values for text columns based on their string comparisons in python.
If you only want the max values for all the numerical columns in the dataframe, pass numeric_only=True to the max() function.
# get max values of only numerical columns print(df.max(numeric_only=True))
Output:
Attempt1 87.03 Attempt2 87.58 Attempt3 85.44 Attempt4 83.10 Attempt5 86.67 Attempt6 84.24 dtype: float64
4. Max value between two pandas columns
What if you want to get the maximum value between two columns?
You can do so by using the pandas max() function twice. For example, let’s get the maximum value considering both “Attempt1” and “Attempt2”.
# max value over two columns print(df[['Attempt1', 'Attempt2']].max().max())
Output:
87.58
We get 87.58 as the maximum distance considering the first and the second attempts together.
5. Max value in the entire dataframe
You can also get the single biggest value in the entire dataframe. For example, let’s get the biggest value in the dataframe df irrespective of the column.
# mav value over the entire dataframe print(df.max(numeric_only=True).max())
Output:
87.58
Here we apply the pandas max() function twice. First time to get the max values for each numeric column and then to get the max value among them.
For more on the pandas max() function, refer to its documentation.
With this, we come to the end of this tutorial. The code examples and results presented in this tutorial have been implemented in a Jupyter Notebook with a python (version 3.8.3) kernel having pandas version 1.0.5
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
-

Piyush is a data professional passionate about using data to understand things better and make informed decisions. He has experience working as a Data Scientist in the consulting domain and holds an engineering degree from IIT Roorkee. His hobbies include watching cricket, reading, and working on side projects.
View all posts

Use the pandas idxmax function. It’s straightforward:
>>> import pandas
>>> import numpy as np
>>> df = pandas.DataFrame(np.random.randn(5,3),columns=['A','B','C'])
>>> df
A B C
0 1.232853 -1.979459 -0.573626
1 0.140767 0.394940 1.068890
2 0.742023 1.343977 -0.579745
3 2.125299 -0.649328 -0.211692
4 -0.187253 1.908618 -1.862934
>>> df['A'].idxmax()
3
>>> df['B'].idxmax()
4
>>> df['C'].idxmax()
1
-
Alternatively you could also use
numpy.argmax, such asnumpy.argmax(df['A'])— it provides the same thing, and appears at least as fast asidxmaxin cursory observations. -
idxmax()returns indices labels, not integers. -
Example’: if you have string values as your index labels, like rows ‘a’ through ‘e’, you might want to know that the max occurs in row 4 (not row ‘d’).
-
if you want the integer position of that label within the
Indexyou have to get it manually (which can be tricky now that duplicate row labels are allowed).
HISTORICAL NOTES:
idxmax()used to be calledargmax()prior to 0.11argmaxwas deprecated prior to 1.0.0 and removed entirely in 1.0.0- back as of Pandas 0.16,
argmaxused to exist and perform the same function (though appeared to run more slowly thanidxmax). argmaxfunction returned the integer position within the index of the row location of the maximum element.- pandas moved to using row labels instead of integer indices. Positional integer indices used to be very common, more common than labels, especially in applications where duplicate row labels are common.
For example, consider this toy DataFrame with a duplicate row label:
In [19]: dfrm
Out[19]:
A B C
a 0.143693 0.653810 0.586007
b 0.623582 0.312903 0.919076
c 0.165438 0.889809 0.000967
d 0.308245 0.787776 0.571195
e 0.870068 0.935626 0.606911
f 0.037602 0.855193 0.728495
g 0.605366 0.338105 0.696460
h 0.000000 0.090814 0.963927
i 0.688343 0.188468 0.352213
i 0.879000 0.105039 0.900260
In [20]: dfrm['A'].idxmax()
Out[20]: 'i'
In [21]: dfrm.iloc[dfrm['A'].idxmax()] # .ix instead of .iloc in older versions of pandas
Out[21]:
A B C
i 0.688343 0.188468 0.352213
i 0.879000 0.105039 0.900260
So here a naive use of idxmax is not sufficient, whereas the old form of argmax would correctly provide the positional location of the max row (in this case, position 9).
This is exactly one of those nasty kinds of bug-prone behaviors in dynamically typed languages that makes this sort of thing so unfortunate, and worth beating a dead horse over. If you are writing systems code and your system suddenly gets used on some data sets that are not cleaned properly before being joined, it’s very easy to end up with duplicate row labels, especially string labels like a CUSIP or SEDOL identifier for financial assets. You can’t easily use the type system to help you out, and you may not be able to enforce uniqueness on the index without running into unexpectedly missing data.
So you’re left with hoping that your unit tests covered everything (they didn’t, or more likely no one wrote any tests) — otherwise (most likely) you’re just left waiting to see if you happen to smack into this error at runtime, in which case you probably have to go drop many hours worth of work from the database you were outputting results to, bang your head against the wall in IPython trying to manually reproduce the problem, finally figuring out that it’s because idxmax can only report the label of the max row, and then being disappointed that no standard function automatically gets the positions of the max row for you, writing a buggy implementation yourself, editing the code, and praying you don’t run into the problem again.
17 авг. 2022 г.
читать 1 мин
Вы можете использовать следующие методы, чтобы вернуть строку кадра данных pandas, содержащую максимальное значение в определенном столбце:
Метод 1: вернуть строку с максимальным значением
df[df['my_column'] == df['my_column']. max ()]
Метод 2: вернуть индекс строки с максимальным значением
df['my_column']. idxmax ()
В следующих примерах показано, как использовать каждый метод на практике со следующими пандами DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],
'points': [18, 22, 19, 14, 14, 11, 28, 20],
'assists': [5, 7, 7, 9, 12, 9, 9, 4],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]})
#view DataFrame
print(df)
team points assists rebounds
0 A 18 5 11
1 B 22 7 8
2 C 19 7 10
3 D 14 9 6
4 E 14 12 6
5 F 11 9 5
6 G 28 9 9
7 H 20 4 12
Пример 1: возвращаемая строка с максимальным значением
В следующем коде показано, как вернуть строку в DataFrame с максимальным значением в столбце точек :
#return row with max value in points column
df[df['points'] == df['points']. max ()]
team points assists rebounds
6 G 28 9 9
Максимальное значение в столбце точек равно 28 , поэтому была возвращена строка, содержащая это значение.
Пример 2: возвращаемый индекс строки с максимальным значением
В следующем коде показано, как вернуть только индекс строки с максимальным значением в столбце точек :
#return row that contains max value in points column
df['points']. idxmax ()
6
Строка в позиции индекса 6 содержала максимальное значение в столбце точек , поэтому было возвращено значение 6 .
Связанный: Как использовать функцию idxmax() в Pandas (с примерами)
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в pandas:
Как найти максимальное значение по группе в Pandas
Как найти максимальное значение столбцов в Pandas