Обновлено 01.04.2019
Ошибка vsphere ha virtual machine monitoring error
Всем привет сегодня расскажу, как решается и из-за чего выскакивает ошибка vsphere ha virtual machine monitoring error и vsphere ha virtual machine monitoring action. Данная ошибка вполне может перезагрузить виртуальную машину, нештатно завершив все рабочие процессы, ладно если это случиться в вечернее время, с минимальными последствиями для клиентов, а если в самый час пик, это очень сильно ударит по репутации компании и может повлечь денежные убытки.
Вот более наглядное представление этих ошибок в VMware vCenter 5.5.
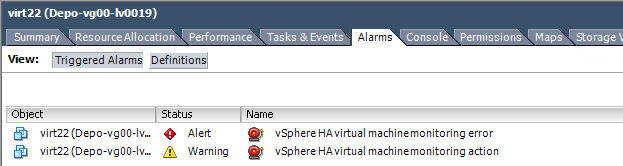
Ошибка vsphere ha virtual machine monitoring error-02
Видим сначала идет предупреждение и потом alert
vsphere ha virtual machine monitoring error
vsphere ha virtual machine monitoring action
Анализ log файла
Сначала нужно проанализировать лог файл виртуальной машины, для этого щелкаем правым кликом по datastore и выбираем browse datastore
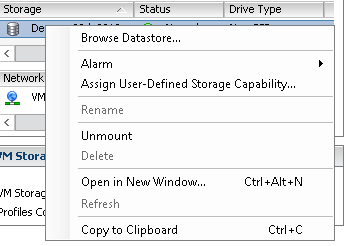
browse datastore vmware
Переходим в нужную папку виртуальной машины и находим там файл vmware.log
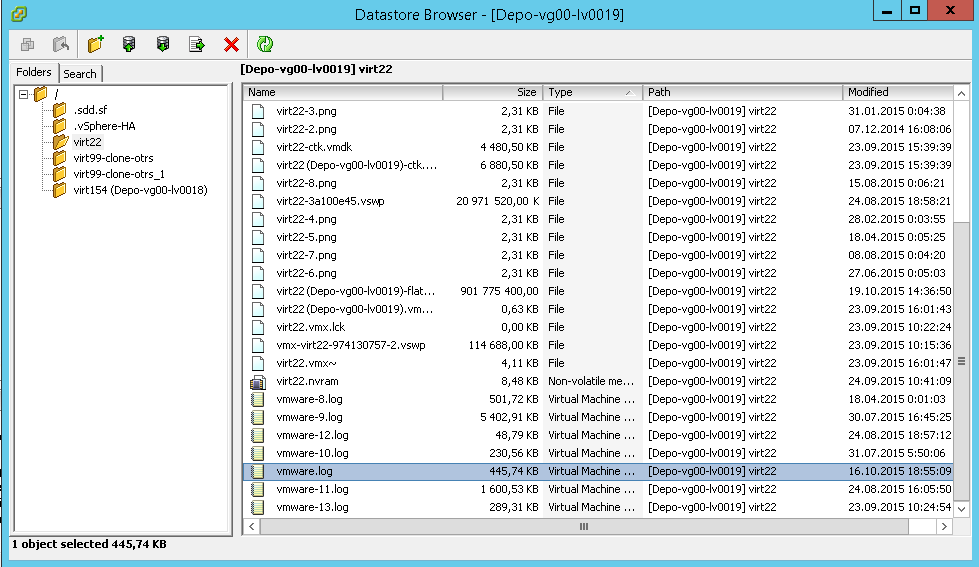
ищем vmware.log
Этот файл vmware.log, нам нужно скачать, сделать это можно к сожалению только на выключенной виртуальной машине, щелкаем по нему правым кликом и выбираем Download
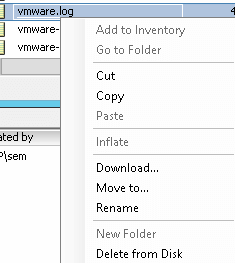
скачиваем лог файл
Указываем место куда нужно закачать ваш файл, для дальнейшего изучения. Все ошибки в данном файле в большинстве случаев сводятся к необходимости обновить vmware tools
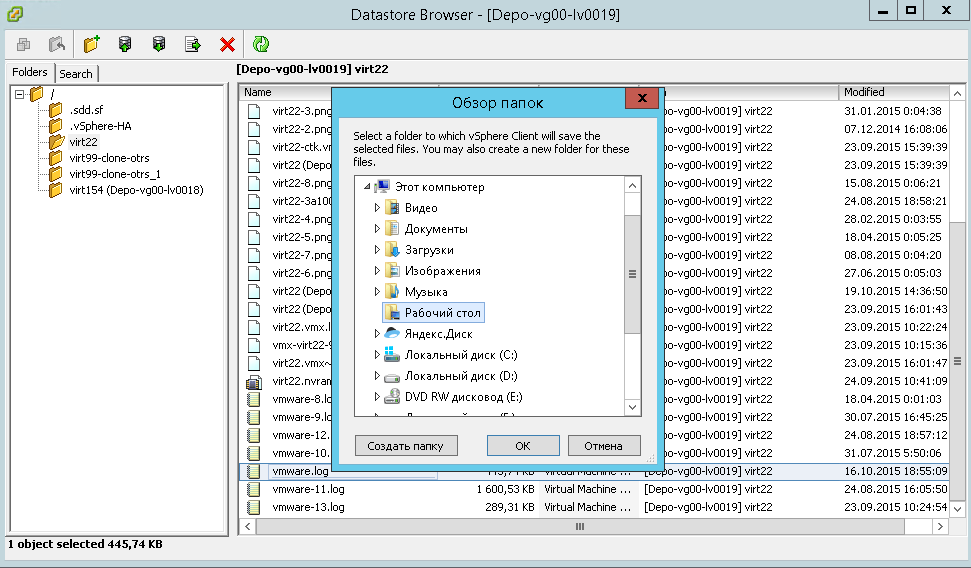
сохранение vmware.log
То же самое вы можете увидеть и на Vmware ESXI 6.5. (VMware Tools is not installed on this virtual machine)
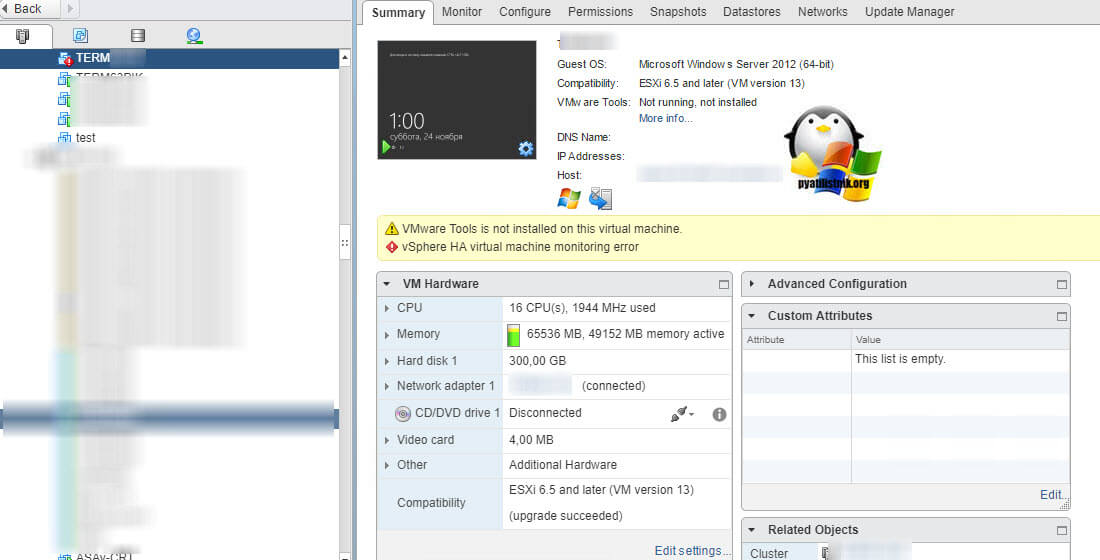
Обновление vmware tools
Напомню vmware tools это пакет драйверов который устанавливается внутри виртуальной машины для лучшей интеграции и расширения функционала. Как обновить vmware tools в VMware ESXI 5.5 я рассказывал ранее. Еще отмечу, что вначале вам придется удалить Vmware Tools из гостевой операционной системы, так как смонтировать диск с дистрибутивом для обновления вы не сможете, так как поле будет не активно.
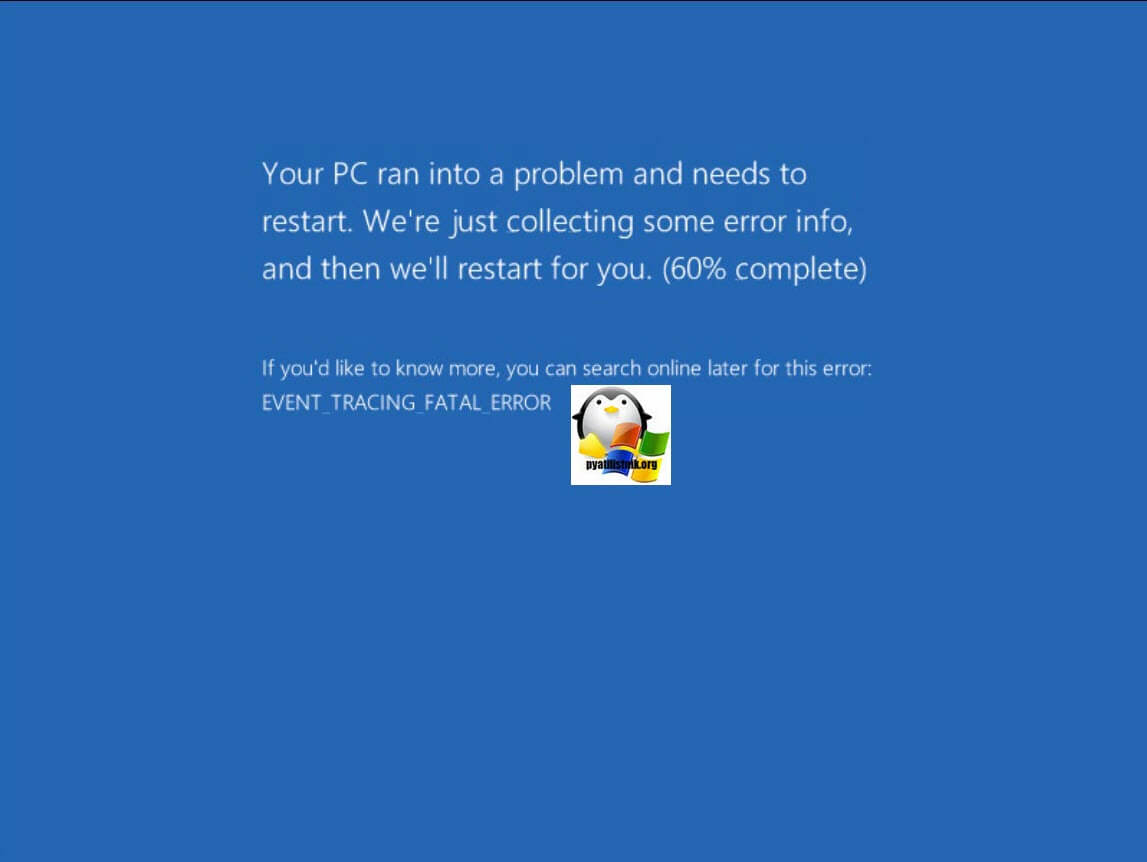
Так же если вы будите медлить с решением данной проблемы, вы будите постоянно ловить синий экран с кодом 0x00000050. При его анализе он будет ругаться на драйвера.
Надеюсь что вы теперь поняли из за чего происходит alert vsphere ha virtual machine monitoring error. Материал сайта pyatilistnik.org
We had also enabled this parameter in our environment and we started getting too many alerts however the vm’s were just fine.
We then disabled it
any slight change in the vm can trigger it. Not necessary the vm has to be down. This is just a warning.
Enable the error setting and talk/discuss to colleagues to disable it
![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Possible Reason: The Alarm is stuck. It needs to be reset. It may be a known bug with version ESX 4.0 Update 1.
Fix: Change the Frequency of the Alarm to 1 minute. This resets the alarm. If everything is ok, the alarm will no longer be stuck. Set back to original time. (5 Minutes)
- Click vCenter
- Go to the Alarms Tab
- Go to the Actions Tab
- Change “Repeat Actions Every: 5 minutes” to 1 minute.
- Confirm after 5 minutes it is no longer sending out alerts.
- Change back to 5 minutes.
- This should resolve the issue
If you found this information useful, please consider awarding points for «Correct» or «Helpful». Thanks!
![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
View Triggered Alarms and Alarm Definitions
Triggered alarms are visible in several locations throughout the vSphere Client and vSphere Web Client. Alarm definitions are accessible only through the vSphere Client.
Prerequisites
You must have a vSphere Web Client or a vSphere Client connected to a vCenter Server.
Procedure
|
♦ |
Perform the following actions for the client you are using:
|
http://pubs.vmware.com/vsphere-50/index.jsp?topic=/com.vmware.vsphere.install.doc_50/GUID-48AC6D6A-B…
If you found this information useful, please consider awarding points for «Correct» or «Helpful». Thanks!

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am also unable to modify the Alarm Frequency, as it is greyed out. Disabling and re-enabling the «vSphere HA virtual machine failover failed» alarm fixed the problem for me.
At the vCenter level select the Alarms tab, Edit the settings of the alarm, select the General tab, disabled/re-enable the alarm.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do you see the VC as the «defined in» value for this alarm? If it’s defined for a datacenter or something like that you would experience this behavior.
«Alarm settings are read only except when accessed through the object where they were defined.»
Check it out and let us know, also a screenshot of the alarms/alarm settings page may be of value.
Regards,
Larry
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I went to edit and it was greyed out. I noticed that it said «changing these options will clear current trigger list» on the General Tab. I unchecked Enable, clicked ok, then went back and enabled it. Seems fine.
I am getting these warnings as well every time I restart my vSphere server. Resetting them every time is easy — but why?! Any correct solution instead of this work around??
Версия 7.0U1 vSAN стала доступна с 6 октября 2020 года. Многим удалось уже протестировать ее на практике, кто-то – в самом разгаре подготовки к апгрейду этого замечательного решения для хранения данных, а другие еще только находятся в процессе знакомства с ним. И, без сомнения, всем им будет полезен материал о траблшутинге VMware vSAN 7.0U1.
Несмотря на то, что вендор, без преувеличения, относится к этому продукту с особым трепетом и старается всеми силами сделать его идеальным, ошибок в нем еще встречается немало, как и проблем с внедрением и применением. Что ж, сегодня мы постараемся всех их перечислить, и, по возможности, предложить действенные пути решения.
- Issue: vSAN идет вразрез с принципами HA vSphere, позволяя пользователям разворачивать виртуальные машины одновременно и на локальном, и на удаленном хранилище данных. Например, можно развернуть один VMDK на локальном хранилище vSAN, и один – на удаленном.
Resolve: Не позволять пользователям разворачивать диски в разных по типу расположения местах.
- Issue: Сводная информация о хранилище хоста не включает в себя хранилища данных vSAN. Если зайти на станицу «Summary» ESXi-хоста, «Storage summary» по свободным, использованным значениям и значениям емкости не включает доступные с этого хоста хранилища vSAN.
Resolve: Информацию о хранилище vSAN можно посмотреть в «Summary» кластера.
- Issue: Задача переформатирования объекта зависла и не прогрессирует. При переформатировании объектов vSAN переконфигурирует их формат в фоновом режиме. Перенастраиваются такие объекты целыми партиями, и процесс зависит от доступной для кластера транзитной емкости. Когда емкость задач выходит за свой лимит, vSAN ждет ее очистки перед продолжением переформатирования.
Resolve: нет. На самом деле задача выполнится, просто – в свое время.
- Issue: Системные виртуальные машины не выключаются. vSphere Cluster Services (vCLS) в апдейте 7.0U1 позволяет размещать набор системных машин в кластере vSAN. Пользователям запрещено их отключать, так как это действие может оказать неблагоприятное влияние на ряд описанных здесь рабочих процессов vSAN.
Resolve: Проблема и работа с ней описаны в материале.
- Issue: Внутренняя сеть докера vSAN File Services VM (FSVM) может перекрываться пользовательской сетью, не выдавая сообщение о том, что нужна реконфигурация. Вызывает проблемы с маршрутизацией трафика к корректной конечной точке.
Resolve: Указать другую сеть для файловой службы (отличную от 172.17.0.0/16).
- Issue: Некоторые задачи развертывания файловых служб виртуальной машины (FSVM) могут фейлиться во время включения дедупликации или шифрования/компрессии на кластере, где доступна vSAN File Service. Указанные процессы вызывают Disk Format Change (DFC), который поочередно отключает FSVM на каждом хосте. В то же время ESX Agent Manager (EAM) пытается развернуть FSVM и тогда получается сбой.
Resolve: Эти сбои можно игнорировать. Когда завершится DFC, исправление FSVM будет успешным.
- Issue: Deep Rekey может прервать пользовательские процессы ввода/вывода. Речь об операциях NFS- и SMB-пользователей.
Resolve: Если это критично, перенести процесс Deep Rekey в окно maintenance.
- Issue: Файловые службы vSAN не могут быть включены из-за старой версии формата on-disk (древнее 11.0).
Resolve: Обновить версию формата диска.
- Issue: Удаление файлов не отображается в емкости vSAN. Освобожденные блоки не возвращаются в хранилище vSAN, даже если оттуда удалены все файлы. Они могут повторно использоваться, когда новые данные будут записываться на тот же общий файловый ресурс.
Resolve: Для возвращения этого хранилища в vSAN, следует удалить общие файловые ресурсы.
- Issue: Исправление задачи кластера большого размера может сбоить из-за проблем с тестированием здоровья сети vSAN. Речь о кластерах с более чем 16-ю хостами и задачах обновления хоста. Тогда пинги не проходят, и обновление хоста в vSphere Life Cycle Manager прерывается.
Resolve: После пре-чека отключить оповещения для следующих тестов vSAN:
-
- vSAN: Basic (unicast) connectivity check
- vSAN: MTU check (ping with large packet size).
Когда обновление завершится, восстановить эти оповещения.
- Issue: Хост сбоит в сценарии смены диска «на горячую», когда повторно вставляется диск. Когда диск NVMe извлекается таким образом и вставляется менее чем через минуту, хост падает.
Resolve: Подождать более одной минуты.
- Issue: Update Manager показывает ID теста вместо имени. В процессе использования Update Manager для обновления хостов в vSAN кластере, хелс-чеки vSAN могут выявить проблемы с ним и выдать сообщение, к примеру, вида:
Before host exits MM, remediation failed because vSAN health check failed. vSAN cluster is not healthy because vSAN health check(s): com.vmware.vsan.health.test.controlleronhcl failed
Resolve: Использовать службу проверки здоровья для идентификации и решения проблем. Затем запустить обновление хоста снова. Больше об использовании проверок здоровья vSAN при работе с vSphere Update Manager (VUM) можно почитать здесь.
- Issue: Невозможно перевести последний хост в кластере в режим обслуживания, удалить диск или дисковую группу. Когда только один хост остался в кластере, а тот ушел на maintenance, операции в режиме «Full data migration» или «Ensure accessibility» могут завершаться ошибкой, не предложив добавить новый ресурс. Аналогичное случается, когда только один диск или дисковая группа остались в кластере, и их нужно удалить.
Resolve: До перевода последней оставшейся в кластере ноды в режим обслуживания с выбранными опциями «Full data migration» и «Ensure accessibility», добавить другой хост такой же конфигурации в кластер. Перед удалением последнего оставшегося диска или дисковой группы, добавить новый диск или группу такой же конфигурации и емкости.
- Issue: Рабочие процессы реконфигурации объектов могут фейлиться из-за недостатка емкости одного или большего количества дисков (дисковых групп), если они почти заполнены. Ресинхронизация vSAN становится на паузу, если диски в кластерах с дедупликацией или без нее достигают своих настраиваемых пороговых значений заполненности паузы ресинхронизации. Это сделано для того, чтобы избежать переполнения дисков при операциях ввода/вывода ресинхронизации. Останавливаются все рабочие процессы вроде EMM, восстановления, ребаланса и изменения политик.
Resolve: Если в другом месте кластера все еще есть свободное пространство, выполнить повторную ребалансировку для освобождения места другим дискам. Тогда дальше реконфигурация пройдет успешно.
- Issue: После восстановления из переполненного кластера виртуальные машины могут потерять HA-защиту. Если диски заполнены на 100% на хостах кластера vSAN, на ВМ подвисает вопрос и, следовательно, может утратиться защита НА. Также машины с подвисшим вопросом не защищаются НА после восстановления из полного кластерного сценария.
Resolve: После восстановления в результате полного кластерного сценария vSAN выполнить одно из трех:
-
- Выключить и включить НА;
- Реконфигурировать НА;
- Выключить и включить виртуальные машины.
- Issue: Сбой выключения ВМ с «Question Pending». Если у машины есть неразрешенный вопрос, любые связанные с ней операции недоступны, пока на него не будет дан ответ.
Resolve: Освободить дисковое пространство на соответствующем томе, после чего нажать «Retry».
- Issue: При заполнении кластера IP-адреса ВМ меняются на IPV6 или становятся недоступными. При заполнении кластера vSAN (одна или несколько дисковых групп достигают 100%) задается вопрос к пользователю, требующий определенных его действий в качестве ответа. Если он остается нерешенным или не сделать что-то с заполненностью кластера, IP-адреса виртуальных машин сменятся на IPV6 или станут недоступны. Так было задумано, чтобы предотвратить использование доступа по SSH к ВМ. Консоль, кстати, аналогично недоступна: ввод пароля рута делает консоль пустой.
Resolve: нет.
- Issue: Не получается удалить группу дисков с включенной дедупликацией после перехода емкости диска в статус PDL. То же самое происходит, если поменять уникальный идентификатор диска, или же при выявлении устройством неустранимой аппаратной ошибки.
Resolve: Каждый раз при удалении или изменении уникального идентификатора диска емкости, либо же при возникновении неисправимой аппаратной ошибки, подождать несколько минут и только затем пробовать удалить группу дисков.
- Issue: Состояние vSAN показывает недоступность, связанную с несоответствием при проваленном запросе политики. Это часто случается, когда есть другая запланированная по графику работа, использующая запрошенные ресурсы. По мере того, как ресурсы высвобождаются, vSAN автоматически перестраивает график исполнения запроса этой политики.
Resolve: Как правило, сканирование периода в vSAN устраняет эту проблему автоматически. Однако стоит учитывать, что прочие незавершенные действия могут нуждаться в доступных ресурсах даже после того, как политика была изменена, однако еще не успела примениться. В этом случае рекомендуется добавить емкость (если в отчете о емкости значения слишком высоки).
- Issue: В кластерах с дедупликацией возвратная ребалансировка может не состояться, если диск показывает более 80% заполненности. Это случается потому, что в таких кластерах все, ожидающее записей или удалений, аналогично учитывается при калькуляции свободной емкости.
Resolve: нет.
- Issue: Из гостевой ОС команды TRIM/UNMAP не работают. Если гостевая операционная система пытается восстановить пространство при онлайн-консолидации во время снэпшота, введение команд TRIM/UNMAP завершается ошибкой. В результате место не освобождается.
Resolve: Повторить операцию освобождения места после снятия снэпшота. Если и далее TRIM/UNMAP не работают, перемонтировать диск.
- Issue: Ошибка на хосте при преобразовании хоста данных в хост-свидетель. При превращении кластера vSAN в растянутый кластер, обязательно нужно предоставить ему ноду-свидетеля. Однако в процессе приходится использовать режим maintenance с полной миграцией данных. Если же положить хост в режим обслуживания с опцией «Ensure accessibility» и инициировать конфигурирование ноды-свидетеля, хост падает в «экран смерти».
Resolve: Удалить группу дисков на хосте-свидетеле, а затем заново их создать.
- Issue: Виртуальная машина дублируется с таким же именем в vCenter Server, когда постоянный хост падает в процессе миграции хранилища данных. Если ВМ передает сторадж vMotion из vSAN на другое хранилище данных, к примеру, на NFS, и регистрируется падение хоста в сети vSAN (вызывая аварийное переключение НА на машине), она может продублироваться на vCenter Server.
Resolve: Выключить невалидную виртуальную машину и снять ее регистрацию в vCenter Server.
- Issue: Реконфигурация существующего растянутого кластера под новый vCenter Server вынуждает vSAN выдавать ошибку при проверке состояния (статус «красный»), вида:
vSphere cluster members match vSAN cluster members
Resolve: Проделать следующее:
-
- Подключиться по SSH к хосту-свидетелю;
- Декомиссовать диски на хосте-свидетеле, используя следующую команду:
esxcli vsan storage remove -s «SSD UUID»
-
- Удалить хост-свидетель из кластера по силовому сценарию, командой:
esxcli vsan cluster leave
-
- Реконфигурировать растянутый кластер из нового vCenter Server, пройдя по пути: «Configure > vSAN > Fault Domains & Stretched Cluster».
- Issue: Не удается обновить формат диска во время ресинхронизации vSAN больших объектов. Ошибка вида:
Failed to convert object(s) on vSAN
Resolve: Дождаться завершения ресинхронизации, после проапгрейдить формат диска. Проверить статус ресинхронизации можно в «Monitor > vSAN > Resyncing Components».
- Issue: Последовательная проверка состояния кластера завершается ошибкой во время операции «deep rekey», вида:
Cluster configuration consistency
Эта операция на зашифрованном vSAN-кластере может занять несколько часов. А традиционный хелс-чек не распознает ее, и поэтому выдает ошибку.
Resolve: Провести повторный тест после «deep rekey».
- Issue: Утеря конфигурации растянутого кластера vSAN после выключения vSAN на кластере. Пропадает конфигурация всего: и растянутого кластера, и хоста-свидетеля, и fault domain.
Resolve: Реконфигурировать растянутый кластер после включения.
- Issue: Выключенная ВМ показывается как недоступная при замене хоста-свидетеля. Такое отображается только краткий промежуток времени, а после завершения процесса вновь все проявляются. С запущенными все нормально.
Resolve: нет. Рабочему процессу не вредит.
- Issue: Не получается перевести хосты с неисправным загрузочным носителем в режим обслуживания. vSAN не может сохранить изменения в конфигурации, поэтому выдает ошибку. В логах пишется:
Lost Connectivity to the device xxx backing the boot filesystem
Resolve: Вручную переместить дисковые группы с каждого хоста, используя опцию «Full data evacuation». После положить хост в maintenance mode.
- Issue: Служба проверки состояния не работает, если в кластере vSAN есть ESXi-хосты с vSphere 6.0 Update 1 или старше. vSAN 6.6 и свежее не работает с такими версиями.
Resolve: Не добавлять хосты с такой версией среды или обновить хосты до более поздней версии.
- Issue: После аварийного переключения растянутого кластера виртуальные машины на основном сайте регистрируют ошибку:
Failed to failover
Если второй сайт в растянутом кластере падает, ВМ должны аварийно переключаться на основной.
Resolve: нет. Игнорировать. Не влияет на успешность аварийного переключения.
- Issue: Во время создания партиций сети компоненты на активном сайте кажутся отсутствующими. В процессе деления сети в хосте vSAN или растянутом кластере в веб-клиенте vSphere отображается кластер с точки зрения неактивного сайта.
Resolve: Использовать RVC-команды, чтобы проявить реальное состояние объектов (например, «vsan.vm_object_info»).
- Issue: Некоторые объекты не отвечают требованиям после принудительного восстановления. Это случается потому, что в процессе собственник таких объектов был перемещен на другую ноду. Силовой метод восстановления для таких объектов может примениться с задержкой.
Resolve: Выполнить принудительное восстановление после того, как все прочие объекты будут восстановлены и ресинхронизированы. Подождать, пока vSAN не доделает до конца эту работу.
- Issue: При перемещении узла из одного зашифрованного кластера в другой, а затем назад, задача не выполняется. Ошибка вида:
A general system error occurred: Invalid fault
Так получается потому, что vSAN не в состоянии повторно зашифровать данные на узле, так как пытается использовать исходный ключ шифрования. Спустя немного времени исходный ключ на хосте восстанавливается, после чего все отключенные диски в кластере монтируются.
Resolve: Перезагрузить хост и подождать, пока все диски не смонтируются.
- Issue: Появляется дисбаланс растянутого кластера после восстановления сайта. Иногда при восстановлении сайта на растянутом кластере хосты с упавшего сайта возвращаются последовательно в течение долгого периода времени. vSAN может чрезмерно использовать некоторые хосты при восстановлении их утерянных компонентов.
Resolve: Восстановить все хосты на отказавшем сайте вместе в свободном от операций окне.
- Issue: Сбой операций ВМ из-за проблем с НА на растянутом кластере. В некоторых сценариях сбоя в растянутых кластерах затрагиваются определенные операции виртуальных машин (vMotion или включение машины). Такие сценарии могут включать частичное или полное падение сайта, отказ высокоскоростной связи между сайтами. Это возникает по причине зависимости от доступности VMware HA для нормальной работы сайтов растянутых кластеров.
Resolve: Отключить vSphere HA до выполнения vMotion, создания виртуальных машин или их включения. Затем обратно включить.
- Issue: Невозможно выполнить deep rekey отключенной дисковой группы. Дело в том, что перед deep rekey vSAN делает shallow rekey. А последний не умеет работать с демонтированными дисковыми группами. Соответственно, и deep rekey не стартует.
Resolve: Перемонтировать или удалить отключенную дисковую группу.
- Issue: Логи свидетельствуют, что конфигурация брандмауэра изменилась. Появляется новый вход брандмауэра в профиле безопасности при включенном шифровании vSAN («vsanEncryption»). Это правило контролирует, как хосты связываются напрямую с KMS. Когда такое случается в логи («/var/log/vobd.log») записывается следующее сообщение:
Firewall configuration has changed. Operation ‘addIP4’ for rule set vsanEncryption succeeded.
Firewall configuration has changed. Operation ‘removeIP4’ for rule set vsanEncryption succeeded.
Resolve: нет. Можно игнорировать.
- Issue: Отказ НА не случается после установки параметра «Traffic Type» на vmknic с целью поддержки трафика свидетеля.
Resolve: Вручную отключить vSphere HA на кластере, а затем снова включить.
- Issue: Не поддерживается iSCSI MCS. Целевая служба vSAN iSCSI не поддерживает Multiple Connections per Session (MCS).
Resolve: нет.
- Issue: Любой инициатор iSCSI может обнаруживать цели iSCSI.
Resolve: Можно заизолировать свои ESXi-хосты от инициаторов iSCSI путем помещения их в отдельную VLAN.
- Issue: После создания сетевого раздела, некоторые операции ВМ на связанных клонах могут фейлиться. Речь об операциях, которые не производят I/O. А именно: снятии снэпшотов и приостановке виртуальных машин. Это случается, когда сетевой раздел уже готов, а пространство имен родительской машины еще недоступно. Когда же оно станет доступным, НА не считает нужным включать такую ВМ.
Resolve: Выключить и снова включить ВМ, которые неактивно используют операции ввода/вывода.
- Issue: Нельзя перевести узел-свидетель в Maintenance Mode. Ошибка вида:
A specified parameter was not correct
Resolve: При инициации режима обслуживания для хоста-свидетеля выбрать опцию «No data migration».
- Issue: Перемещение хоста-свидетеля в растянутый кластер и из него оставляет кластер в неправильно сконфигурированном состоянии.
Resolve: Переместить witness-хост вовне растянутого кластера vSAN и переконфигурировать растянутый кластер. Подробнее почитать можно здесь.
- Issue: Когда сетевая партиция появляется в кластере с НА heartbeat хранилищем данных, виртуальные машины не рестартуют на другом сайте данных. Если в vSAN-кластере для основного или вторичного сайта падает сетевое подключение к другим сайтам, работающие на них машины теряют сеть, но не перезапускаются на другом сайте. Ошибка вида:
vSphere HA virtual machine HA failover failed
Resolve: Когда конфигурируется vSphere HA на кластере, не выбирать НА heartbeat хранилище данных.
- Issue: Отключенные диски и дисковые группы vSAN отображаются как подключенные в поле «Client Operational Status» веб-клиента vSphere. Если диски или дисковые группы отключены командой:
esxcli vsan storage disk group unmount
или службой vSAN Device Monitor после демонстрации ими постоянных высоких задержек, веб-клиент vSphere некорректно показывает их статус («mounted»).
Resolve: Использовать поле «Health» для проверки статуса дисков вместо поля «Client Operational Status».
Если найдем еще какие-то интересные проблемы с vSAN 7.0U1, обязательно обновим этот материал. Как и в том случае, когда поймем, как решить задачи, на которые выше не было дано ответа.
Hi,
I’ve updated all my vmWare 5.5 hosts and now most of my virtual servers are displaying ‘vSphere HA virtual machine failover failed’ errors … Dis- and enabling the HA option in the properties of the cluster do not make this go away, nor does ‘reconfigure for vSphere HA’
VMware
Experts Exchange is like having an extremely knowledgeable team sitting and waiting for your call. Couldn’t do my job half as well as I do without it!
Unlimited question asking, solutions, articles and more.
Experts Exchange has (a) saved my job multiple times, (b) saved me hours, days, and even weeks of work, and often (c) makes me look like a superhero! This place is MAGIC!
Walt Forbes
Not exactly the question you had in mind?
Sign up for an EE membership and get your own personalized solution. With an EE membership, you can ask unlimited troubleshooting, research, or opinion questions.
ask a question
Unlimited question asking, solutions, articles and more.
I started with Experts Exchange in 2004 and it’s been a mainstay of my professional computing life since. It helped me launch a career as a programmer / Oracle data analyst
William Peck
Unlimited question asking, solutions, articles and more.
Обновлено 01.04.2019

Ошибка vsphere ha virtual machine monitoring error
Всем привет сегодня расскажу, как решается и из-за чего выскакивает ошибка vsphere ha virtual machine monitoring error и vsphere ha virtual machine monitoring action. Данная ошибка вполне может перезагрузить виртуальную машину, нештатно завершив все рабочие процессы, ладно если это случиться в вечернее время, с минимальными последствиями для клиентов, а если в самый час пик, это очень сильно ударит по репутации компании и может повлечь денежные убытки.
Вот более наглядное представление этих ошибок в VMware vCenter 5.5.

Ошибка vsphere ha virtual machine monitoring error-02
Видим сначала идет предупреждение и потом alert
vsphere ha virtual machine monitoring error
vsphere ha virtual machine monitoring action
Анализ log файла
Сначала нужно проанализировать лог файл виртуальной машины, для этого щелкаем правым кликом по datastore и выбираем browse datastore

browse datastore vmware
Переходим в нужную папку виртуальной машины и находим там файл vmware.log

ищем vmware.log
Этот файл vmware.log, нам нужно скачать, сделать это можно к сожалению только на выключенной виртуальной машине, щелкаем по нему правым кликом и выбираем Download

скачиваем лог файл
Указываем место куда нужно закачать ваш файл, для дальнейшего изучения. Все ошибки в данном файле в большинстве случаев сводятся к необходимости обновить vmware tools

сохранение vmware.log
То же самое вы можете увидеть и на Vmware ESXI 6.5. (VMware Tools is not installed on this virtual machine)

Обновление vmware tools
Напомню vmware tools это пакет драйверов который устанавливается внутри виртуальной машины для лучшей интеграции и расширения функционала. Как обновить vmware tools в VMware ESXI 5.5 я рассказывал ранее. Еще отмечу, что вначале вам придется удалить Vmware Tools из гостевой операционной системы, так как смонтировать диск с дистрибутивом для обновления вы не сможете, так как поле будет не активно.

Так же если вы будите медлить с решением данной проблемы, вы будите постоянно ловить синий экран с кодом 0x00000050. При его анализе он будет ругаться на драйвера.

Надеюсь что вы теперь поняли из за чего происходит alert vsphere ha virtual machine monitoring error. Материал сайта pyatilistnik.org

Всем привет сегодня расскажу как решается и из за чего выскакивает ошибка vsphere ha virtual machine monitoring error и vsphere ha virtual machine monitoring action. Данная ошибка вполне может перезагрузить виртуальную машину. Ошибка vsphere ha virtual machine monitoring error — http://pyatilistnik.org/oshibka-vsphere-ha-virtual-machine-monitoring-error/

Являюсь автором проекта Windows, будь вкурсе всего, который насчитывает за пол года уже более 1000 статей.
Смотреть все записи автора cinquefoil2014

Hi friends today we are going discuses about the Vsphere HA Virtual Machine Monitoring error.
This is one of a series of KB articles that provide information about default vSphere alarms for virtual machines. Default vSphere alarms are set on the vCenter Server level and propagated to all child objects in the inventory.
| Alarm name | Trigger conditions | Actions |
| vSphere HA virtual machine monitoring error | vSphere HA cannot reset VM | Send a notification trap (Repeat) |
If action is required, address the root cause of the condition that triggered the alarm. See Creating and Using vSphere HA Clusters.
1.Right click the esi host where the VM is hosted and click on the reconfigure for vsphereHA

